diff --git a/LICENSE.md b/LICENSE
similarity index 96%
rename from LICENSE.md
rename to LICENSE
index 38420b1..60c1e93 100644
--- a/LICENSE.md
+++ b/LICENSE
@@ -1,6 +1,6 @@
MIT License
-Copyright (c) 2020 The Rubix ML Community
+Copyright (c) 2020 Rubix ML
Copyright (c) 2020 Andrew DalPino
Permission is hereby granted, free of charge, to any person obtaining a copy
diff --git a/README.md b/README.md
index 4acfc61..56d7391 100644
--- a/README.md
+++ b/README.md
@@ -96,7 +96,7 @@ $losses = $estimator->steps();
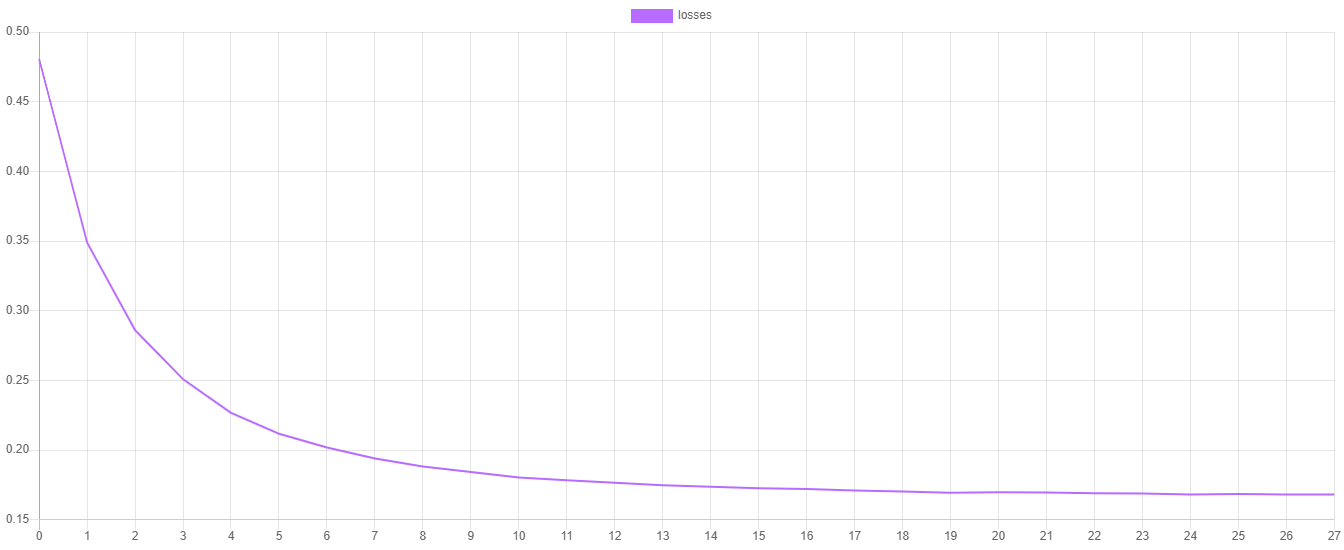
You'll notice that the loss should be decreasing at each epoch and changes in the loss value should get smaller the closer the learner is to converging on the minimum of the cost function.
-
+
### Cross Validation
Once the learner has been trained, the next step is to determine if the final model can generalize well to the real world. For this process, we'll need the testing data that we set aside earlier. We'll go ahead and generate two reports that compare the predictions outputted by the estimator with the ground truth labels from the testing set.
@@ -276,12 +276,12 @@ $stats->toJSON()->write('stats.json');
### Visualizing the Dataset
The credit card dataset has 25 features and after one hot encoding it becomes 93. Thus, the vector space for this dataset is *93-dimensional*. Visualizing this type of high-dimensional data with the human eye is only possible by reducing the number of dimensions to something that makes sense to plot on a chart (1 - 3 dimensions). Such dimensionality reduction is called *Manifold Learning* because it seeks to find a lower-dimensional manifold of the data. Here we will use a popular manifold learning algorithm called [t-SNE](https://docs.rubixml.com/en/latest/embedders/t-sne.html) to help us visualize the data by embedding it into only two dimensions.
-We don't need the entire dataset to generate a decent embedding so we'll take 2,000 random samples from the dataset and only embed those. The `head()` method on the dataset object will return the first *n* samples and labels from the dataset in a new dataset object. Randomizing the dataset beforehand will remove the bias as to the sequence that the data was collected and inserted.
+We don't need the entire dataset to generate a decent embedding so we'll take 2,500 random samples from the dataset and only embed those. The `head()` method on the dataset object will return the first *n* samples and labels from the dataset in a new dataset object. Randomizing the dataset beforehand will remove the bias as to the sequence that the data was collected and inserted.
```php
use Rubix\ML\Datasets\Labeled;
-$dataset = $dataset->randomize()->head(2000);
+$dataset = $dataset->randomize()->head(2500);
```
### Instantiating the Embedder
@@ -325,7 +325,7 @@ $ php explore.php
Here is an example of what a typical 2-dimensional embedding looks like when plotted.
-
+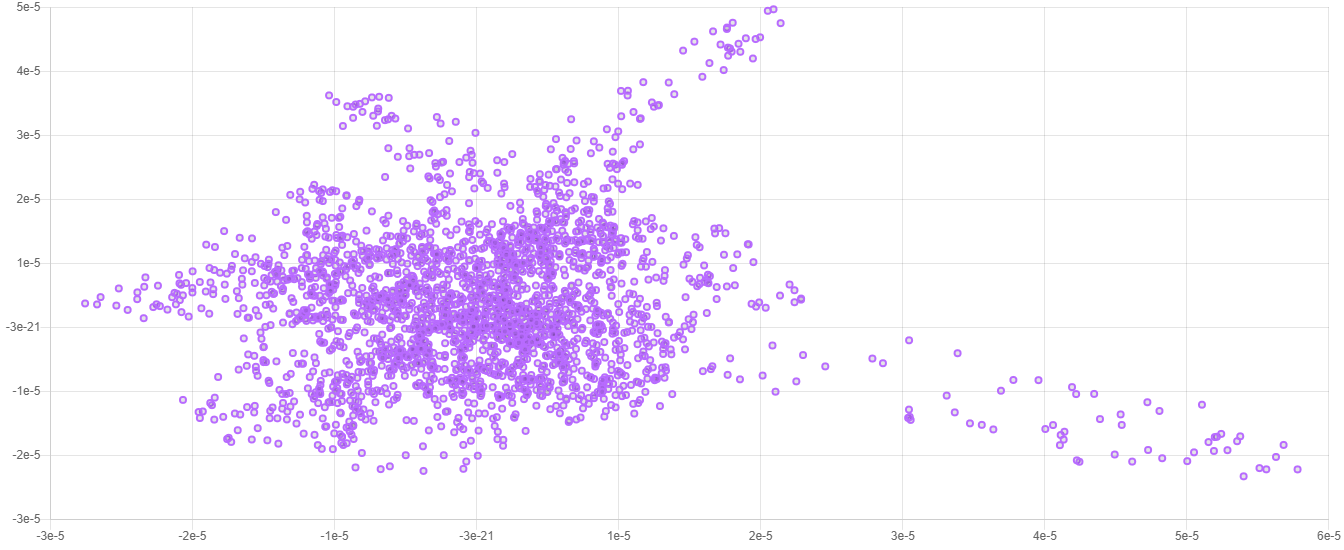
> **Note**: Due to the stochastic nature of the t-SNE algorithm, every embedding will look a little different from the last. The important information is contained in the overall *structure* of the data.
@@ -345,4 +345,4 @@ Institutions: (1) Department of Information Management, Chung Hua University, Ta
>- Dua, D. and Graff, C. (2019). UCI Machine Learning Repository [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
## License
-The code is licensed [MIT](LICENSE.md) and the tutorial is licensed [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/).
\ No newline at end of file
+The code is licensed [MIT](LICENSE) and the tutorial is licensed [CC BY-NC 4.0](https://creativecommons.org/licenses/by-nc/4.0/).
\ No newline at end of file
diff --git a/composer.json b/composer.json
index a5b8e8b..f42067e 100644
--- a/composer.json
+++ b/composer.json
@@ -3,7 +3,7 @@
"type": "project",
"description": "An example project that predicts the risk of credit card default using a Logistic Regression classifier and a 30,000 sample dataset of credit card customers.",
"homepage": "https://github.com/RubixML/Credit",
- "license": "Apache-2.0",
+ "license": "MIT",
"keywords": [
"classification", "classifier", "credit score", "cross validation", "dataset", "data science",
"data visualization", "default risk prediction", "dimensionality reduction", "example project",
@@ -13,17 +13,13 @@
"authors": [
{
"name": "Andrew DalPino",
- "email": "me@andrewdalpino.com",
- "homepage": "https://andrewdalpino.com",
+ "homepage": "https://github.com/andrewdalpino",
"role": "Lead Engineer"
}
],
"require": {
"php": ">=7.2",
- "rubix/ml": "^0.1.0"
- },
- "suggest": {
- "ext-tensor": "For faster training and inference"
+ "rubix/ml": "^0.3.0"
},
"scripts": {
"explore": "@php explore.php",
diff --git a/docs/images/embedding.png b/docs/images/embedding.png
new file mode 100644
index 0000000..443b441
Binary files /dev/null and b/docs/images/embedding.png differ
diff --git a/docs/images/embedding.svg b/docs/images/embedding.svg
deleted file mode 100644
index 621277f..0000000
--- a/docs/images/embedding.svg
+++ /dev/null
@@ -1,4078 +0,0 @@
-
-
-
\ No newline at end of file
diff --git a/docs/images/training-loss.png b/docs/images/training-loss.png
new file mode 100644
index 0000000..3148d90
Binary files /dev/null and b/docs/images/training-loss.png differ
diff --git a/docs/images/training-loss.svg b/docs/images/training-loss.svg
deleted file mode 100644
index 77e7d71..0000000
--- a/docs/images/training-loss.svg
+++ /dev/null
@@ -1,126 +0,0 @@
-
-
-
\ No newline at end of file
diff --git a/explore.php b/explore.php
index d81099f..f553230 100644
--- a/explore.php
+++ b/explore.php
@@ -27,7 +27,7 @@
$logger->info('Stats saved to stats.json');
-$dataset = $dataset->randomize()->head(2000);
+$dataset = $dataset->randomize()->head(2500);
$embedder = new TSNE(2, 20.0, 20);