Using Apache Kafka & OpenTelemetry Collector for better burst handling for observability data
On a recent thread on the CNCF Slack’s OTel Collector channel, a user asked a question that shone a light on a topic I don't think has been effectively discussed elsewhere.
This article will discuss both multi-collector architecture and how Apache Kafka can be useful here.

Doesn't collector tiering make more sense, generally, than using a queue?
(Big thank you to Martin for always being there with a helpful answer.)
To review, the OpenTelemetry Collector is an optional but strongly recommended part of an OpenTelemetry observability deployment. The collector can gather, compress, manage, and filter data sent by OpenTelemetry instrumentation before data gets sent to your observability backend. If sending data to the SigNoz backend, the system will look something like this:
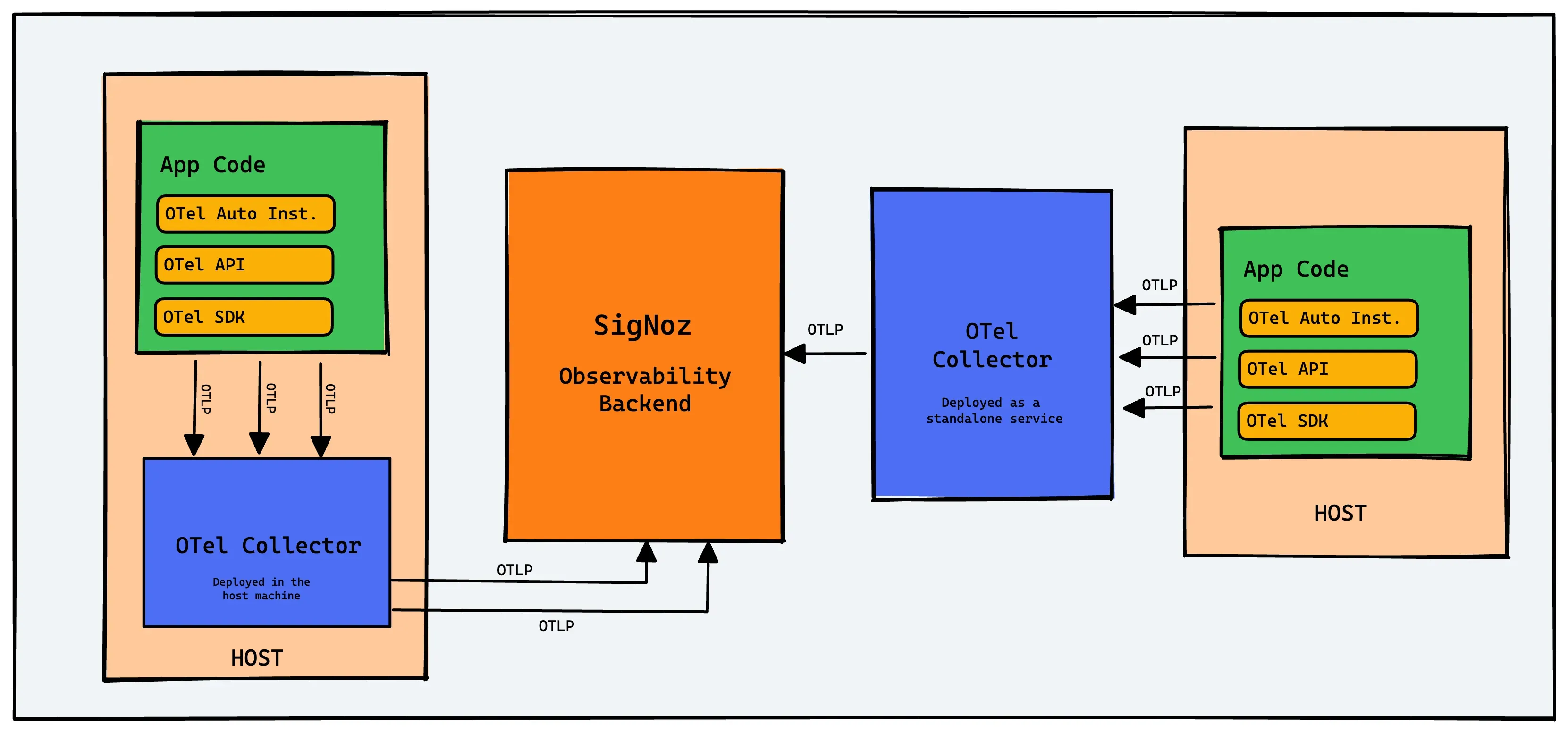
Calls from OpenTelemetry auto-instrumentation, API calls, and other code instrumented with the OpenTelemetry SDK all go to the collector running on a host.
In more advanced cases, however, this may not be sufficient. Imagine an edge service that handles high-frequency requests, sending regular requests to a fairly distant collector on the same network. The result will be errors raised on the app when it fails to reach the collector for every single request.
Again, the whole benefit of the collector is that it should be able to cache, batch, and compress data for sending, no matter how high-frequency its data ingest.
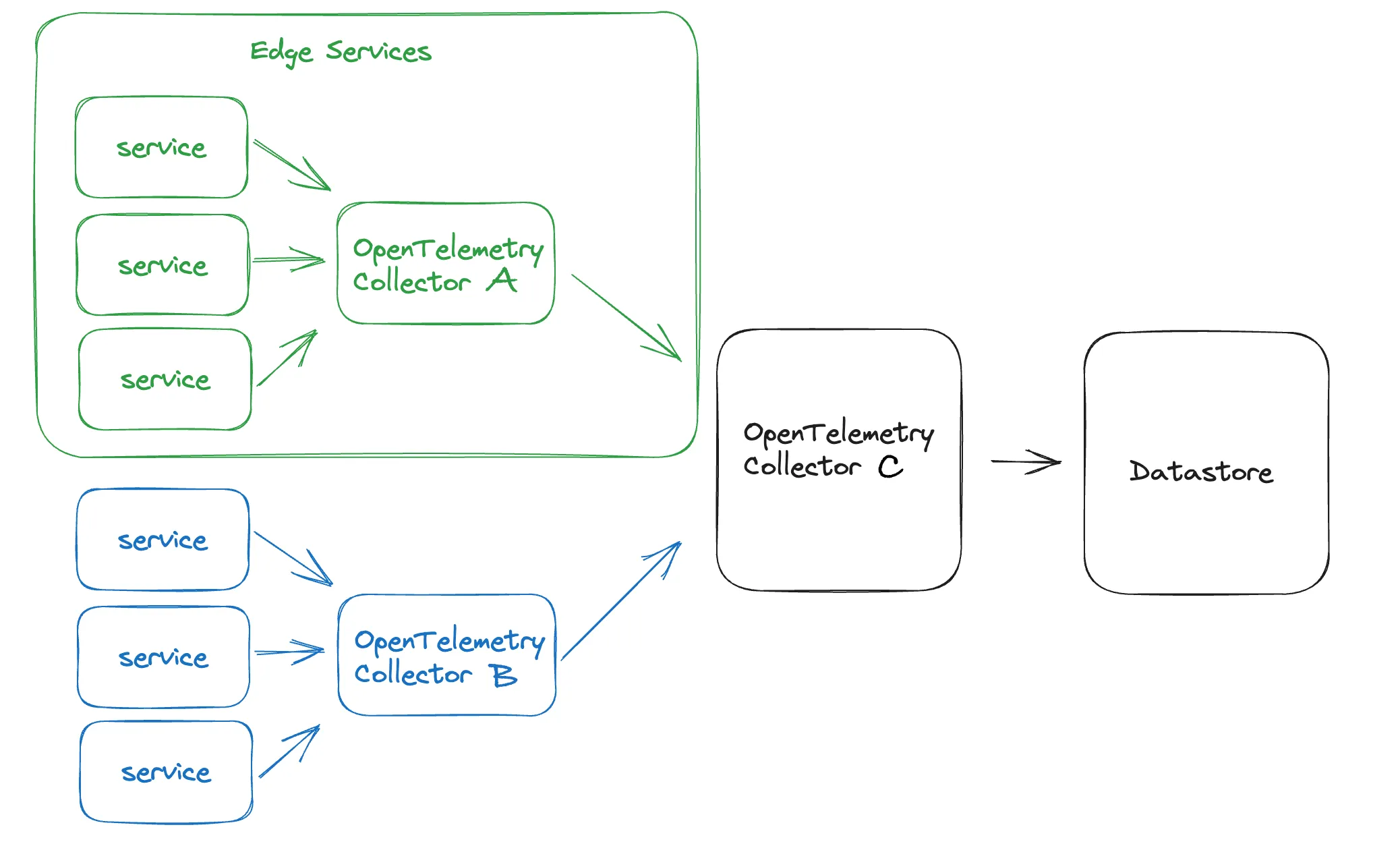
This has a number of advantages:
-
Scalability: In large-scale distributed systems, a single OpenTelemetry collector might not be sufficient to handle the volume of telemetry data generated by all the services and applications.
-
Reduced Network Traffic: For every additional step of filtering that happens within your network, you reduce the total amount of network bandwidth used for observability.
-
Filtering and Sampling: With a multi-tiered approach, you can perform data filtering, transformation, or sampling at the intermediate collector before forwarding the data to the central collector. This can be done by teams who know the microservices under instrumentation and what data is important to highlight. Alternatively, if you have an issue like PII showing up from multiple services, you can set filtering on the central collector to make sure the rules are followed everywhere.
In the Slack thread above, the proposed solution was to use something like a Kafka queue. This would have the advantage of ingesting events reliably and almost never raising errors. Both an internal queue and a collector-to-collector architecture are ways to improve the reliability of your observability data. The two scenarios where a Kafka Queue makes the most sense for your data are:
- Ensuring data collection during database outages - even reliable databases fail, and Kafka can ingest and store data during the outage. When the DB is up again, the consumer can start taking in data again.
- Handling traffic bursts - observability data can spike during a usage spike, and if you're doing deep tracing, the spike can be even larger in scale than the increase in traffic. If you scale your database to handle this spike without any queuing, the DB will be over-provisioned for normal traffic. A queue will buffer the data spike so that the database can handle it when it's ready.
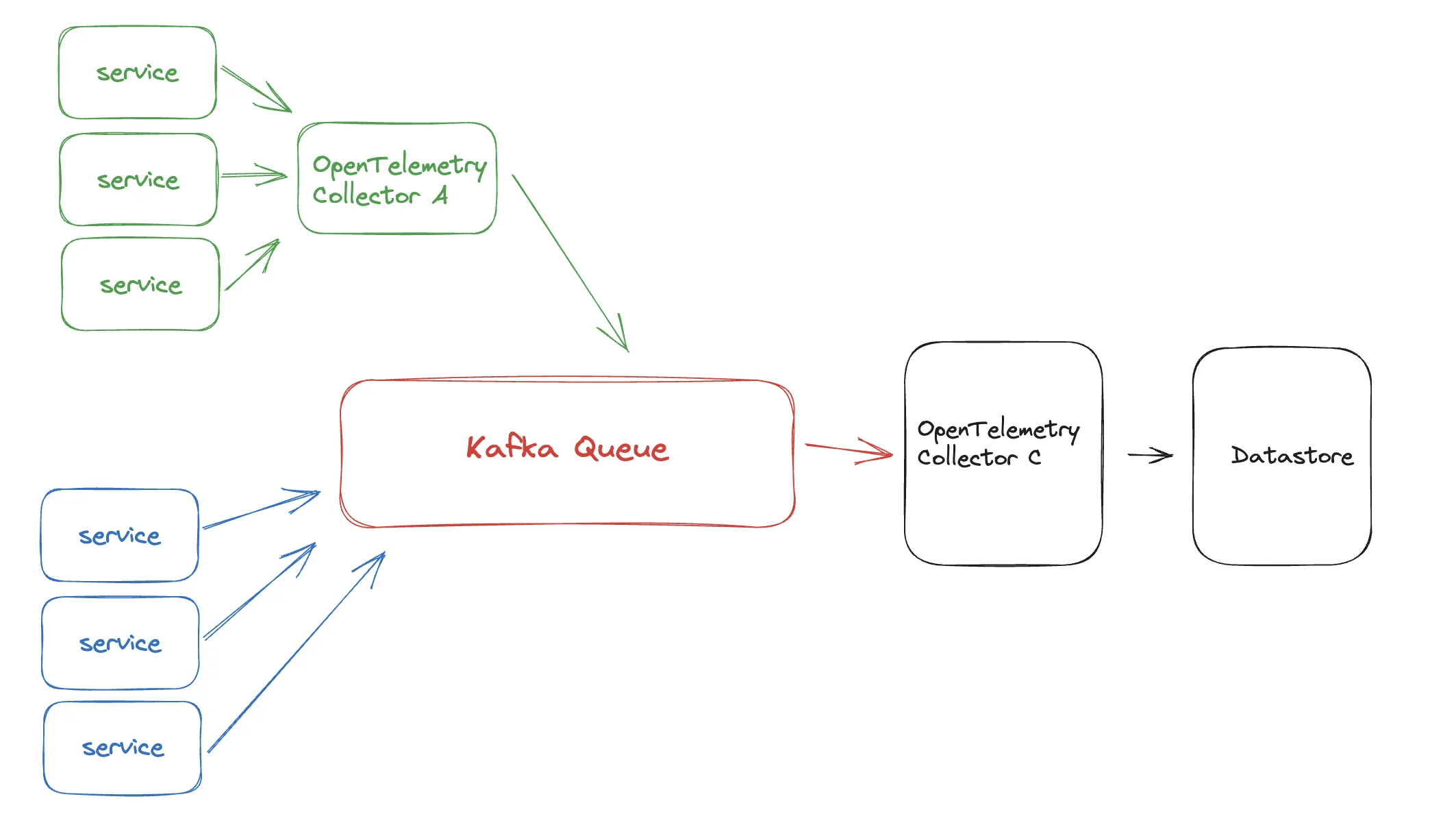
To learn more about the options for receiving data from Kafka, see the Kafka receiver in the OpenTelemetry Collector Contrib repository.
The process for implementing multiple collectors should be straightforward. If doing this from scratch, it would require the following config for Service A, Intermediate Collector B, and Central Collector C:
apiVersion: apps/v1
kind: Deployment
metadata:
name: intermediate-collector
labels:
app: intermediate-collector
spec:
replicas: 1
selector:
matchLabels:
app: intermediate-collector
template:
metadata:
labels:
app: intermediate-collector
spec:
containers:
- name: intermediate-collector
image: your-intermediate-collector-image:latest
ports:
- containerPort: 55678 # Replace with the appropriate port numberapiVersion: apps/v1
kind: Deployment
metadata:
name: intermediate-collector
labels:
app: intermediate-collector
spec:
replicas: 1
selector:
matchLabels:
app: intermediate-collector
template:
metadata:
labels:
app: intermediate-collector
spec:
containers:
- name: intermediate-collector
image: your-intermediate-collector-image:latest
ports:
- containerPort: 55678 # Replace with the appropriate port numberapiVersion: apps/v1
kind: Deployment
metadata:
name: central-collector
labels:
app: central-collector
spec:
replicas: 1
selector:
matchLabels:
app: central-collector
template:
metadata:
labels:
app: central-col
lector
spec:
containers:
- name: central-collector
image: your-central-collector-image:latest
ports:
- containerPort: 55678 # Replace with the appropriate port numberThe intermediate collector will send telemetry data to the central collector using OTLP.
The choice between OpenTelemetry Collector and Apache Kafka isn't a zero-sum game. Each has its unique strengths and can even complement each other in certain architectures. The OpenTelemetry Collector excels in data gathering, compression, and filtering, making it a strong candidate for reducing in-system latency and improving data quality before it reaches your backend.
Apache Kafka shines in scenarios where high reliability and data buffering are critical, such as during database outages or traffic spikes. Kafka's robust queuing mechanism can act as a valuable intermediary, ensuring that no data is lost and that databases are not over-provisioned.
The multi-collector architecture discussed offers a scalable and efficient way to handle large volumes of telemetry data. By positioning collectors closer to the services being monitored, you can reduce network traffic and enable more effective data filtering. This architecture can be further enhanced by integrating a Kafka queue, which adds another layer of reliability and scalability.