-
Notifications
You must be signed in to change notification settings - Fork 1
/
08_Building Evaluation Dataframe using Review App Data.py
136 lines (104 loc) · 5.69 KB
/
08_Building Evaluation Dataframe using Review App Data.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
# Databricks notebook source
# MAGIC %md
# MAGIC #Evaluation Driven Development
# MAGIC 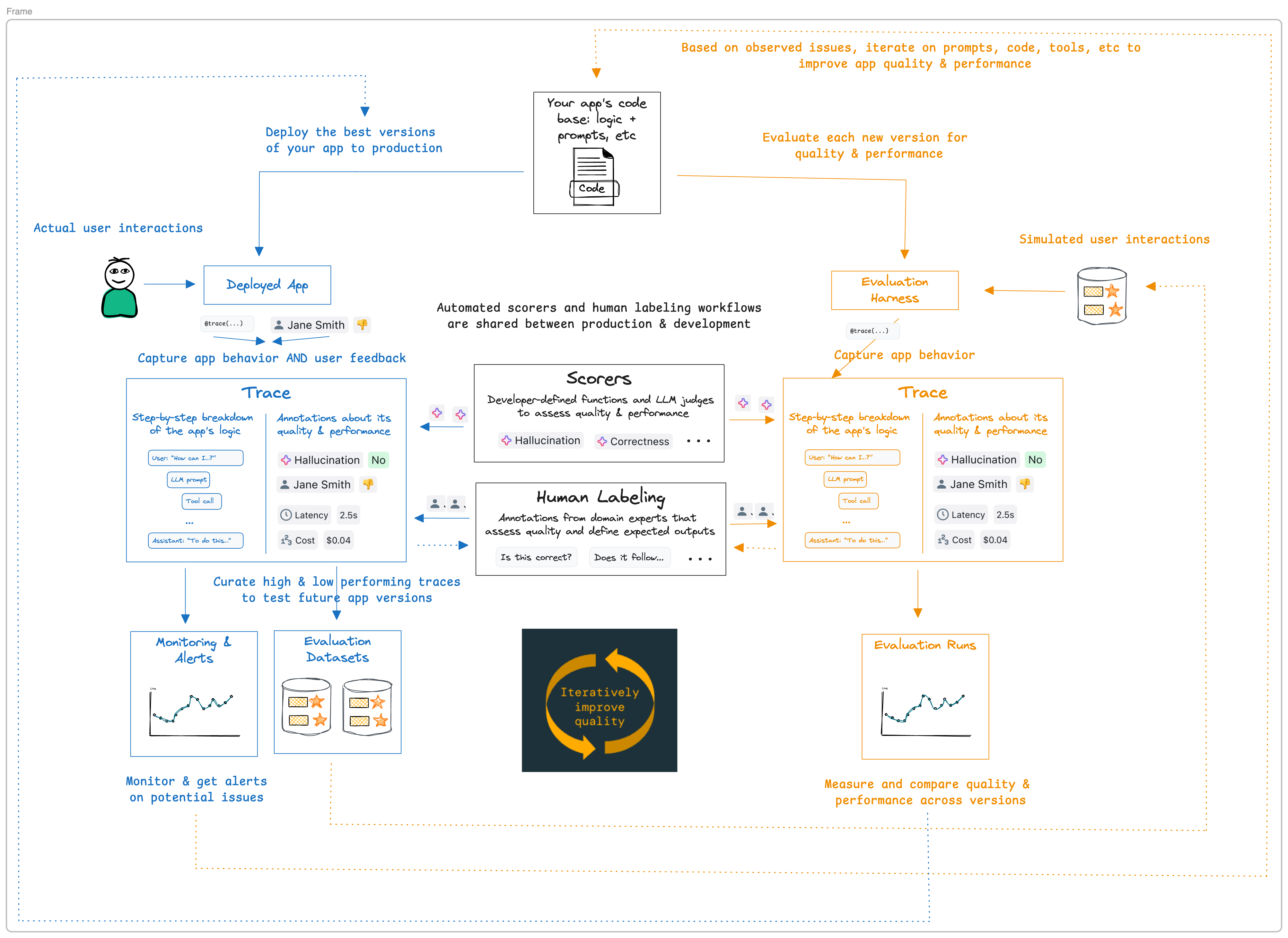
# MAGIC
# MAGIC Evaluation Driven Workflow is based on the Mosaic Research team’s recommended best practices for building and evaluating high-quality RAG applications.
# MAGIC
# MAGIC Databricks recommends the following evaluation-driven workflow:
# MAGIC 1. Define the requirements.
# MAGIC 2. Collect stakeholder feedback on a rapid proof of concept (POC).
# MAGIC 3. Evaluate the POC’s quality.
# MAGIC 4. Iteratively diagnose and fix quality issues.
# MAGIC 5. Deploy to production.
# MAGIC 6. Monitor in production.
# MAGIC
# MAGIC [Read More](https://docs.databricks.com/en/generative-ai/tutorials/ai-cookbook/evaluation-driven-development.html)
# MAGIC
# MAGIC #Review App and Getting Human Feedback
# MAGIC The Databricks Review App stages the agent in an environment where expert stakeholders can interact with it - in other words, have a conversation, ask questions, and so on. In this way, the review app lets you collect feedback on your application, helping to ensure the quality and safety of the answers it provides.
# MAGIC
# MAGIC Stakeholders can chat with the application bot and provide feedback on those conversations, or provide feedback on historical logs, curated traces, or agent outputs.
# MAGIC
# MAGIC [Read more](https://docs.databricks.com/en/generative-ai/agent-evaluation/human-evaluation.html)
# MAGIC
# MAGIC One of the core concepts of Evaluation Driven Workflow is to objectively measure quality of the model. Reviews captured by the review app can now serve as a basis to create a better evaluation dataframe for our Agent as we iterate to improve quality. This notebook demonstrates that process.
# COMMAND ----------
# MAGIC %md ### Review App Logs to Evaluation Set
# MAGIC
# MAGIC This step will bootstrap an evaluation set with the feedback that stakeholders have provided by using the Review App. Note that you can bootstrap an evaluation set with *just* questions, so even if your stakeholders only chatted with the app vs. providing feedback, you can follow this step.
# MAGIC
# MAGIC Visit [documentation](https://docs.databricks.com/generative-ai/agent-evaluation/evaluation-set.html#evaluation-set-schema) to understand the Agent Evaluation Evaluation Set schema - these fields are referenced below.
# MAGIC
# MAGIC At the end of this step, you will have an Evaluation Set that contains:
# MAGIC
# MAGIC 1. Requests with a 👍 :
# MAGIC - `request`: As entered by the user
# MAGIC - `expected_response`: If the user edited the response, that is used, otherwise, the model's generated response.
# MAGIC 2. Requests with a 👎 :
# MAGIC - `request`: As entered by the user
# MAGIC - `expected_response`: If the user edited the response, that is used, otherwise, null.
# MAGIC 3. Requests without any feedback e.g., no 👍 or 👎
# MAGIC - `request`: As entered by the user
# MAGIC
# MAGIC
# COMMAND ----------
# MAGIC %run ./utils/eval_set_utils
# COMMAND ----------
# MAGIC %md ### Get the request and assessment log tables
# MAGIC
# MAGIC These tables are updated every ~hour with data from the raw Inference Table.
# COMMAND ----------
model_name = "carecost_compass_agent"
registered_model_name = f"{catalog}.{schema}.{model_name}"
w = WorkspaceClient()
active_deployments = agents.list_deployments()
active_deployment = next(
(item for item in active_deployments if item.model_name == registered_model_name), None
)
endpoint = w.serving_endpoints.get(active_deployment.endpoint_name)
try:
endpoint_config = endpoint.config.auto_capture_config
except AttributeError as e:
endpoint_config = endpoint.pending_config.auto_capture_config
inference_table_name = endpoint_config.state.payload_table.name
inference_table_catalog = endpoint_config.catalog_name
inference_table_schema = endpoint_config.schema_name
# Cleanly formatted tables
assessment_log_table_name = f"{inference_table_catalog}.{inference_table_schema}.`{inference_table_name}_assessment_logs`"
request_log_table_name = f"{inference_table_catalog}.{inference_table_schema}.`{inference_table_name}_request_logs`"
print(f"Assessment logs: {assessment_log_table_name}")
print(f"Request logs: {request_log_table_name}")
assessment_log_df = _dedup_assessment_log(spark.table(assessment_log_table_name))
request_log_df = spark.table(request_log_table_name)
# COMMAND ----------
# MAGIC %md
# MAGIC ### ETL the request & assessment logs into Evaluation Set schema
# MAGIC
# MAGIC Note: We leave the complete set of columns from the request and assesment logs in this table - you can use these for debugging any issues.
# COMMAND ----------
requests_with_feedback_df = create_potential_evaluation_set(request_log_df, assessment_log_df)
requests_with_feedback_df.columns
# COMMAND ----------
# MAGIC %md
# MAGIC ### Inspect the potential evaluation set using MLflow Tracing
# MAGIC
# MAGIC Click on the `trace` column in the displayed table to view the Trace. You should inspect these records
# COMMAND ----------
display(requests_with_feedback_df.select(
F.col("request_id"),
F.col("request"),
F.col("response"),
F.col("trace"),
F.col("expected_response"),
F.col("expected_retrieved_context"),
F.col("is_correct"),
))
# COMMAND ----------
# MAGIC %md
# MAGIC ### Save the resulting evaluation set to a Delta Table
# COMMAND ----------
eval_set = requests_with_feedback_df[["request", "request_id", "expected_response", "expected_retrieved_context", "source_user", "source_tag"]]
eval_table_name = f"{catalog}.{schema}.eval_data_{model_name}"
spark.sql(f"DROP TABLE IF EXISTS {eval_table_name}")
eval_set.write.format("delta").saveAsTable(eval_table_name)