-
Notifications
You must be signed in to change notification settings - Fork 11
/
040 Multithreading.jl
381 lines (303 loc) · 11.2 KB
/
040 Multithreading.jl
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
import Pkg; Pkg.activate(@__DIR__); Pkg.instantiate()
# # Multithreading
#
# Now we're finally ready to start talking about running things on multiple
# processors! Most computers (even cell phones) these days have multiple cores
# or processors — so the obvious place to start working with parallelism is
# making use of those from within our Julia process.
#
# The first challenge, though, is knowing precisely how many "processors" you have.
# "Processors" is in scare quotes because, well, it's complicated.
versioninfo(verbose = true)
#-
using Hwloc
Hwloc.num_physical_cores()
# What your computer reports as the number of processors might not be the same
# as the total number of "cores". While sometimes virtual processors can add
# performance, parallelizing a typical numerical computation over these virtual
# processors will lead to significantly worse performance because they still
# have to share much of the nuts and bolts of the computation hardware.
#-
# Julia is somewhat multithreaded by default! BLAS calls (like matrix multiplication) are
# already threaded:
using BenchmarkTools
A = rand(1000, 1000);
B = rand(1000, 1000);
@benchmark $A*$B
# This is — by default — already using all your CPU cores! You can see the effect
# by changing the number of threads (which BLAS supports doing dynamically):
using LinearAlgebra
BLAS.set_num_threads(1)
@benchmark $A*$B
BLAS.set_num_threads(4)
@benchmark $A*$B
# ## What does it look like to implement your _own_ threaded algorithm?
using .Threads
nthreads()
# Julia currently needs to start up knowing that it has threading support enabled.
#
# You do that with a environment variable. To get four threads, start Julia with:
#
# ```
# JULIA_NUM_THREADS=4 julia
# ```
run(`env JULIA_NUM_THREADS=4 julia -E 'using .Threads; nthreads()'`)
# The other way to do it is in JuliaPro itself:
#
# * Go to the Julia Menu -> Settings -> Number of Threads
# * By default it'll choose a "good" number for you
threadid()
# So we're currently on thread 1. Of course a loop like this will
# just set the first element to one a number of times:
A = zeros(Int, nthreads())
for i in 1:nthreads()
A[i] = threadid()
end
A
# But if we prefix it with `@threads` then the loop body is divided between threads!
@threads for i in 1:nthreads()
A[i] = threadid()
end
A
# So let's try implementing our first simple threaded algorithm — `sum`:
function threaded_sum1(A)
r = zero(eltype(A))
@threads for i in eachindex(A)
@inbounds r += A[i]
end
return r
end
A = rand(10_000_000)
threaded_sum1(A)
@time threaded_sum1(A)
#-
sum(A)
@time sum(A)
# Whoa! What happened? Not only did we get the wrong answer, it was _slow_ to get it!
function threaded_sum2(A)
r = Atomic{eltype(A)}(zero(eltype(A)))
@threads for i in eachindex(A)
@inbounds atomic_add!(r, A[i])
end
return r[]
end
threaded_sum2(A)
@time threaded_sum2(A)
# Alright! Now we got the correct answer (modulo some floating point associativity),
# but it's still slower than just doing the simple thing on 1 core.
threaded_sum2(A) ≈ sum(A)
# But it's still slow! Using atomics is much slower than just adding integers
# because we constantly have to go and check _which_ processor has the latest
# work! Also remember that each thread is running on its own processor — and
# that processor also supports SIMD! Well, that is if it didn't need to worry
# about syncing up with the other processors...
function threaded_sum3(A)
r = Atomic{eltype(A)}(zero(eltype(A)))
len, rem = divrem(length(A), nthreads())
@threads for t in 1:nthreads()
rₜ = zero(eltype(A))
@simd for i in (1:len) .+ (t-1)*len
@inbounds rₜ += A[i]
end
atomic_add!(r, rₜ)
end
# catch up any stragglers
result = r[]
@simd for i in length(A)-rem+1:length(A)
@inbounds result += A[i]
end
return result
end
threaded_sum3(A)
@time threaded_sum3(A)
# Dang, that's complicated. There's also a problem:
threaded_sum3(rand(10) .+ rand(10)im) # try an array of complex numbers!
# Isn't there an easier way?
R = zeros(eltype(A), nthreads())
#-
function threaded_sum4(A)
R = zeros(eltype(A), nthreads())
@threads for i in eachindex(A)
@inbounds R[threadid()] += A[i]
end
r = zero(eltype(A))
# sum the partial results from each thread
for i in eachindex(R)
@inbounds r += R[i]
end
return r
end
threaded_sum4(A)
@time threaded_sum4(A)
# This sacrifices our ability to `@simd` so it's a little slower, but at least we don't need to worry
# about all those indices! And we also don't need to worry about atomics and
# can again support arrays of any elements:
threaded_sum4(rand(10) .+ rand(10)im)
# ## Key takeaways from `threaded_sum`:
#
# * Beware shared state across threads — it may lead to wrong answers!
# * Protect yourself by using atomics (or [locks/mutexes](https://docs.julialang.org/en/v1/base/multi-threading/#Synchronization-Primitives-1))
# * Better yet: divide up the work manually such that the inner loops don't
# share state. `@threads for i in 1:nthreads()` is a handy idiom.
# * Alternatively, just use an array and only access a single thread's elements
#-
# # Beware of global state (even if it's not obvious!)
#
# Another class of algorithm that you may want to parallelize is a monte-carlo
# problem. Since each iteration is a new random draw, and since you're interested
# in looking at the aggregate result, this seems like it should lend itself to
# parallelism quite nicely!
using BenchmarkTools
#-
function serialpi(n)
inside = 0
for i in 1:n
x, y = rand(), rand()
inside += (x^2 + y^2 <= 1)
end
return 4 * inside / n
end
serialpi(1)
@time serialpi(100_000_000)
# Let's use the techniques we learned above to make a fast threaded implementation:
function threadedpi(n)
inside = zeros(Int, nthreads())
@threads for i in 1:n
x, y = rand(), rand()
@inbounds inside[threadid()] += (x^2 + y^2 <= 1)
end
return 4 * sum(inside) / n
end
threadedpi(240)
@time threadedpi(100_000_000)
# Ok, now why didn't that work? It's slow! Let's look at the sequence of random
# numbers that we generate:
import Random
Random.seed!(0)
N = 20000
Rserial = zeros(N)
for i in 1:N
Rserial[i] = rand()
end
Rserial
#-
Random.seed!(0)
Rthreaded = zeros(N)
@threads for i in 1:N
Rthreaded[i] = rand()
end
Rthreaded
#-
Set(Rserial) == Set(Rthreaded)
# Aha, `rand()` isn't (currently) threadsafe! It's mutating (and reading) some global each
# time to figure out what to get next. This leads to slowdowns — and worse — it
# skews the generated distribution of random numbers since some are repeated!!
#
# Note: on the upcoming Julia 1.3 it is now threadsafe by default! Here's how
# we can emulate it on prior versions:
const ThreadRNG = Vector{Random.MersenneTwister}(undef, nthreads())
@threads for i in 1:nthreads()
ThreadRNG[Threads.threadid()] = Random.MersenneTwister()
end
function threadedpi2(n)
inside = zeros(Int, nthreads())
len, rem = divrem(n, nthreads())
rem == 0 || error("use a multiple of $(nthreads()), please!")
@threads for i in 1:nthreads()
rng = ThreadRNG[threadid()]
v = 0
for j in 1:len
x, y = rand(rng), rand(rng)
v += (x^2 + y^2 <= 1)
end
inside[threadid()] = v
end
return 4 * sum(inside) / n
end
threadedpi2(240)
@time threadedpi2(100_000_000)
# As an aside, be careful about initializing many `MersenneTwister`s with
# different states. Better to use [`randjump`](https://docs.julialang.org/en/v1/manual/parallel-computing/#Side-effects-and-mutable-function-arguments-1) to skip ahead for a single state.
#-
# # Beware oversubscription
#
# Remember how BLAS is threaded by default? What happens if we try to `@threads`
# something that uses BLAS?
Ms = [rand(1000, 1000) for _ in 1:100]
function serial_matmul(As)
first_idxs = zeros(length(As))
for i in eachindex(As)
@inbounds first_idxs[i] = (As[i]'*As[i])[1]
end
first_idxs
end
serial_matmul(Ms[1:1]);
@time serial_matmul(Ms);
#-
using LinearAlgebra
BLAS.set_num_threads(nthreads()) # Explicitly tell BLAS to use the same number of threads
function threaded_matmul(As)
first_idxs = zeros(length(As))
@threads for i in eachindex(As)
@inbounds first_idxs[i] = (As[i]'*As[i])[1]
end
first_idxs
end
threaded_matmul(Ms[1:1])
@time threaded_matmul(Ms);
#-
BLAS.set_num_threads(1)
@time threaded_matmul(Ms);
#-
@time serial_matmul(Ms) # Again, now that BLAS has just 1 thread
# # Beware "false sharing"
#-
# Remember the memory latency table?
#
#
# | System Event | Actual Latency | Scaled Latency | |
# | ------------------------------ | -------------- | -------------- | ------------------------ |
# | One CPU cycle | 0.4 ns | 1 s | ← work happens here |
# | Level 1 cache access | 0.9 ns | 2 s | |
# | Level 2 cache access | 2.8 ns | 7 s | |
# | Level 3 cache access | 28 ns | 1 min | |
# | Main memory access (DDR DIMM) | ~100 ns | 4 min | ← we have control here |
#
# This is what a typical modern cpu looks like:
#
# 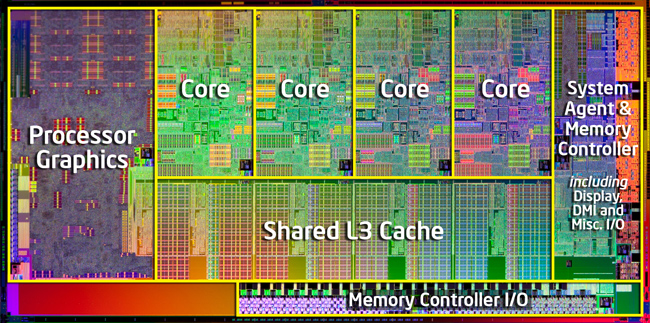
#
# Multiple cores on the same processor share the L3 cache, but do not share L1 and L2 caches! So what happens if we're accessing and mutating data from the same array across multiple cores?
#
# 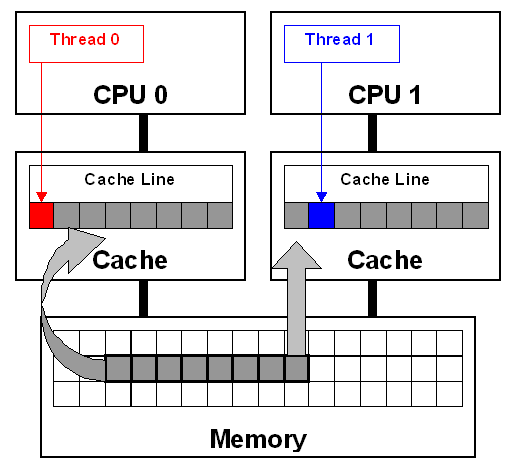
#
# Unlike "true" sharing — which we saw above — false sharing will still return the correct answer! But it does so at the cost of performance. The cores recognize they don't have exclusive access to the cache line and so upon modification they alert all other cores to invalidate and re-fetch the data.
function test(spacing)
a = zeros(Threads.nthreads()*spacing)
b = rand(1000000)
calls = zeros(Threads.nthreads()*spacing)
@threads for i in eachindex(b)
a[Threads.threadid()*spacing] += b[i]
calls[Threads.threadid()*spacing] += 1
end
a, calls
end
@benchmark test(1);
@benchmark test(8);
#-
# ## Further improvements coming here!
#
# PARTR — the threading improvement I discussed at the beginning aims to address
# this problem of having library functions implemented with `@threads` and then
# having callers call them with `@threads`. Uses a state-of-the-art work queue
# mechanism to make sure that all threads stay busy.
#-
# # Threading takeaways:
#
# * It's easy! Just start Julia with `JULIA_NUM_THREADS` and tack a `@threads` on your loop
# * Well, not so fast
# * Be aware of your hardware to set `JULIA_NUM_THREADS` appropiately
# * Beware shared state (for both performance and correctness)
# * Beware global state (but the built-in global state is improving!)
# * Beware false sharing (especially with multiple processor chips)
# * We need to think carefully about how to design parallel algorithms!