Multibyte characters ignored on OS X #1
Comments
|
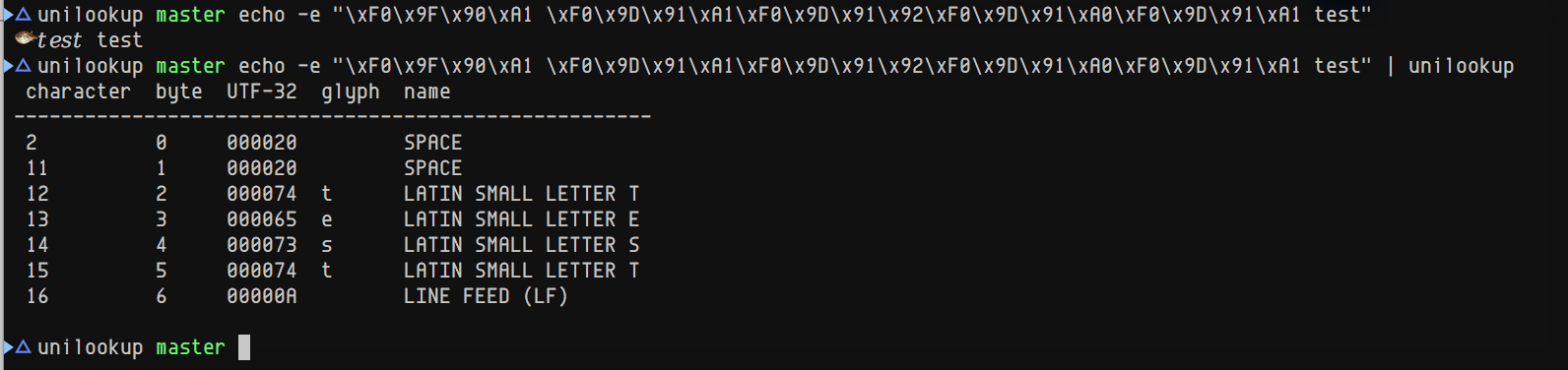
I'm not sure what you're trying to write but afaik u+F09F does not exist. |
|
Each of the first six characters that aren't a space use four bytes, not two: e.g. F0 9F 90 A1, which is u+1F421 (blowfish) |
|
Sorry, my bad. I'm afraid I can't reproduce it.
|

|
@cpsdqs Can you please confirm if this is still an issue in the latest version? Some of the internals have been changed. |
|
sure is |

|
I still cannot reproduce this, which is leading me to think it's a Mac-only issue. Can you try run this on a Linux machine by any chance? |

|
Additionally, could you try prepending |
|
Doesn't work either ¯\_(ツ)_/¯ |
|
Could you try manually setting the input string instead of reading from stdin so we can try figure out where the issue arises? |
|
replacing |

|
Hm, can you try add |
|
prints: (all of them u+FFFD) … (side note: unilookup works fine for |
|
Okay so that seems to be where it breaks, because I'm getting the individual characters on Linux. I'll look into it |
|
From what I've been able to find this is an issue with how Python 2 (on some platforms) handles unicode. The solution here would be to read the byte stream and manually determine byte length (as done here) and then split the byte stream as appropriate. This'll require quite a bit of refactoring to do, but I'll try to get it done soonish. |
Characters with large code points are ignored for some reason. Possibly because they use multiple bytes.
The text was updated successfully, but these errors were encountered: