Releases: openzipkin/zipkin
Zipkin 2.10 completes our v2 migration
Zipkin 2.10 drops v1 library dependency and http read endpoints. Those using the io.zipkin.java:zipkin (v1) java library should transition to io.zipkin.zipkin2:zipkin as the next release of Zipkin will stop publishing updates to the former. Don't worry: Zipkin server will continue accepting all formats, even v1 thrift, for the foreseeable future.
Below is a story of our year long transition to a v2 data format, ending with what we've done in version 2.10 of our server (UI in nature). This is mostly a story of how you address an big upgrade in a big ecosystem when almost all are volunteers.
Before a year ago, the OpenZipkin team endured (and asked ourselves) many confused questions about our thrift data format. Why do service endpoints repeat all the time? What are binary annotations? What do we do if we have multiple similar events or binary annotations? Let's dig into the "binary annotation" as probably many reading still have no idea!
Binary annotations were a sophisticated tag, for example an http status. While the name is confusing, most problems were in being too flexible and this led to bugs. Specifically it was a list of elements with more type diversity than proved useful. While a noble aim, and made sense at the time, binary annotations could be a string, binary, various bit lengths of integer or floating point numbers. Even things that seem obvious could be thwarted. For example, some would accidentally choose the type binary for string, effectively disabling search. Things seemingly simple like numbers were bug factories. For example, folks would add random numbers as an i64, not thinking that you can't fit one in a json number without quoting or losing precision. Things that seemed low-hanging fruit were not. Let's take http status for example. Clearly, this is a number, but which? Is it a 16bit (technically correct) or is it a 32 bit (to avoid signed misinterpretation)? Could you search on it the way you want to (<200 || >299 && !404)? Tricky right? Let's say someone sent it as a different type by accident.. would it mess up your indexing if sent as a string (definitely some will!)? Even if all of this was solved, Zipkin is an open ecosystem including private sites with their private code. How much time does it cost volunteers to help others troubleshoot code that can't be shared? How can we reduce support burden while remaining open to 3rd party instrumentation?
This is a long winded story of how our version 2 data format came along. We cleaned up our data model, simplifying as an attempt to optimize reliability and support over precision. For example, we scrapped "binary annotation" for "tags". We don't let them repeat or use numeric types. There are disadvantages to these choices, but explaining them is cheap and the consequences are well understood. Last July, we started accepting a version 2 json format. Later, we added a protobuf representation.
Now, why are we talking about a data format supported a year ago? Because we just finished! It takes a lot of effort to carefully roll something out into an ecosystem as large as Zipkin's and being respectful of the time impact to our volunteers and site owners.
At first, we ingested our simplified format on the server side. This would "unlock" libraries, regardless of how they are written, and who wrote them, into simpler data.. data that much resembles tracing operations themselves. We next focused on libraries to facilitate sending and receiving data, notably brown field changes (options) so as to neither disrupt folks, nor scare them off. We wanted the pipes that send data to become "v2 ready" so owners can simultaneously use new and old formats, rather than expect an unrealistic synchronous switch of data format. After this, we started migrating our storage and collector code, so that internal functionality resemble v2 constructs even while reading or writing old data in old schemas. Finally, in version 2.10, we changed the UI to consume only v2 data.
So, what did the UI change include? What's interesting about that? Isn't the UI old? Let's start with the last question. While true the UI has only had facelifts and smaller visible features, there certainly has been work involved keeping it going. For example, backporting of tests, restructuring its internal routing, adding configuration hooks or integration patterns. When you don't have UI staff, keeping things running is what you end up spending most time on! More to the point, before 2.10, all the interesting data conversion and processing logic happened in Java, on the api server. For example, merging of data, correcting clock shifts etc. This setup a hard job for those emulating zipkin.. at least those who emulated the read side. Custom read api servers or proxies can be useful in practice. Maybe you need to stitch in authorization or data filtering logic.. maybe your data is segmented.. In short, while most read scenarios are supported out-of-box, some advanced proxies exist for good reason.
Here's a real life example: Yelp saves money by not sending trace data across paid links. For example, in Amazon's cloud (and most others), if you send data from one availability zone to another, you will pay for that. To reduce this type of cost, Yelp uses an island + aggregator pattern to save trace data locally, but materialize traces across zones when needed. In their site, this works particularly well as search doesn't use Zipkin anyway: they use a log based tool to find trace IDs. Once they find a trace ID, they use Zipkin to view it.. but still.. doing so requires data from all zones. To solve this, they made an aggregating read proxy. Before 2.10, it was more than simple json re-bundling. They found that our server did things like merging rules and clock skew correction. This code is complex and also high maintenance, but was needed for the UI to work correctly. Since v2.10 moves this to UI javascript, Yelp's read proxy becomes much simpler and easier to maintain. In summary, having more logic in the UI means less work for those with DIY api servers.
Another advantage of having processing logic in the UI is better answering "what's wrong with this trace?" For example, we know data can be missing or incorrect. When processing is done server-side, there is friction in deciding how to present errors. Do you decorate the trace with synthetic data, or use headers, or some enveloping? If instead that code was in the UI, such decisions are more flexible and don't impact the compatibility of others. While we've not done anything here yet, you can imagine it is easier to show, like color or otherwise, that you are viewing "a bad trace". Things like this are extremely exciting, given our primary goals are usually to reduce the cost of support!
In conclusion, we hope that by sharing our story, you have better insight into the OpenZipkin way of doing things, how we prioritize tasks, and how seriously we take support. If you are a happy user of Zipkin, find a volunteer who's helped you and thank them, star our repository, or get involved if you can. You can always find us on Gitter.
Zipkin 2.9
Zipkin 2.9 reorganizes the project in efforts to reduce future maintenance. This work is important to the long-term health and related to our "v2" project started last year.
If all goes well, the next server release will remove all dependencies on and stop publishing our "v1" library io.zipkin.java:zipkin.
Many thanks to continual support and testing by folks notably @rangwea @llinder and @shakuzen as this ground work was a bit bumpy. On that note, please use the latest patch (at the time of writing 2.9.4)!
Kafka consumers are now v0.10+, not 0.8, by default
We kept Kafka 0.8 support as default for longer than comfortable based on demand from older Zipkin sites. However, this starts to cause problems notably as folks would use the old KAFKA_ZOOKEEPER approach to connecting just because it was default. This also pins versions in a difficult place, notably when the server is extended. The KAFKA_BOOTSTRAP_SERVERS (v0.10+) approach, which was available as an option before, is now the default mechanism in Zipkin.
Those using KAFKA_ZOOKEEPER because they still run old 0.8 brokers can still do so. If you are using Docker, there is no change at all. If you are self-packaging a distribution of zipkin, please use these instructions to integrate v0.8 support.
AWS Elasticsearch Service is now in the zipkin-aws image
Before, our Amazon integration for Elasticsearch was baked into the default image. This was a historical thing because we didn't have a large repository for Amazon components, yet. This caused dual-repository maintenance, particularly Amazon SDK version ping-pong, and also expertise to be somewhat spread arbitrarily in two repositories. zipkin-aws is now the "one stop shop" for Amazon Web Services integrations with Zipkin (or other libraries like Brave for that matter).
Those using ES_AWS_DOMAIN or Amazon endpoints in ES_HOSTS need to use a "zipkin-aws" distribution. If you are using Docker, you just switch your image from openzipkin/zipkin to openzipkin/zipkin-aws. If you are self-packaging a distribution of zipkin, please use these instructions to integrate Amazon's Elasticsearch Service.
"Legacy reads" are now removed from our Elasticsearch storage implementation
Last year, we had to switch our storage strategy in Elasticsearch as multiple type indexes were dropped in future versions of Elasticsearch. We added a temporary ES_LEGACY_READS_ENABLED flag to allow folks to transition easier. This is now removed.
By removing this code, we have more "maintenance budget" do discuss other transitions in Elastcisearch. For example, it is hinted that with a certain version range, re-introducing natural tag indexing could be supported. This would imply yet another transition, which is a bitter pill if we also have to support an older transition.
V1 thrift codec is "re-supported"
You can now read and write old zipkin thrifts using the io.zipkin.zipkin2:zipkin library. This feature is very undesirable from a code maintenance point of view. However, some projects simply weren't upgrading as they are still running or supporting old zipkin backends that only accept thrift. To allow a longer transition period, we introduced the ability to use thrift (and scribe) again on the client side. The first consumer is Apache Camel. Under the scenes SpanBytesEncoder.THRIFT does the job.
Note: If you are still writing v1 thrifts, or using Scribe, please consider alternatives! This is not only to receive better support here, but also the myriad of Zipkin clones. Most clones only accept json, so your products will be more supportable as soon as you can transition off thrift.
Also note: the core jar is still dependency free as we coded the thrift codec directly. A lot of care was taken to pay for this change, by removing other code or sources of bloat from the jar. In fact, our jar is slightly smaller than before we re-added thrift, now a hair below 200KiB.
Storage and Collector extensions are now "v2 only"
Before, we had to support two libraries for integrations such as zipkin-gcp: this implied one path for v1 structs and and another for v2 structs. Now that our core library can read both formats, we could dramatically simplify these integrations. End users won't see any change as a part of this process.
Zipkin 2.8
Zipkin 2.8 migrates to Spring Boot v2 and adds a binary data format (proto3). Do not use a version lower than 2.8.3, as we found some issues post-release and resolved them.
This release is mostly infrastructure. All the help by our community are super appreciated as often such work is hard and thankless. Let's stop that here.. Thank you specifically @zeagord and @shakuzen for working on these upgrades, testing in production and knocking out dents along the way.
Spring Boot and Micrometer update
Zipkin internally has been updated to Spring Boot v2 which implies Micrometer for metrics. While features of our service didn't change, this is an important upgrade and has impact to Prometheus configuration.
Prometheus
We now internally use Micrometer for metrics on Zipkin server. Some of the prometheus metrics have changed to adhere to standards there. Our grafana setup is adjusted on your behalf, but here are some updates if rolling your own:
- Counter metrics now properly have
_totalfor sums- Ex
zipkin_collector_bytes_total, notzipkin_collector_bytes
- Ex
- Collector metrics no longer have embedded fields for transport type
- Ex
zipkin_collector_byteshas a tagtransportinstead of a naming convention
- Ex
- Http metrics now have normalized names
- Ex
http_server_requests_seconds_count, nothttp_requests_total
- Ex
- Http metrics have route-based uri tags
- Ex instead of
pathwhich has variables like/api/v2/trace/abcd,uriwith a template like/ap1/v2/trace/{traceId}
- Ex instead of
Note: the metrics impact is exactly the same prior to the spring boot v2 update. You can update first to Zipkin 2.7.5 to test metrics independently to the other updates.
Endpoint changes
If you were using Spring's "actuator" endpoints, they are now under the path /actuator as described in Spring Boot documentation. However, we've reverse mapped a /metrics and /health endpoint compatible with the previous setup.
Binary Format (protobuf3)
We've had many requests for an alternative to our old thrift format for binary encoding of trace data. Some had interest in the smaller size (typical span data is half the size as uncompressed json). Others had interest in compatibility guarantees. Last year when we created Zipkin v2, we anticipated demand for this, and settled on Protocol Buffers v3 as the format of choice. Due to a surge of demand, we've added this to Zipkin 2.8
Impact to configuration
If using a library that supports this, it is as easy as an encoding choice. For example, switching to Encoding.PROTO3 in your configuration.
NOTE Servers must be upgraded first!
Impact to collectors
Applications will send spans in messages and so our collectors now detect a byte signature of the ListOfSpans type and act accordingly. In http, this is assumed when the content-type application/x-protobuf is used on the /api/v2/spans endpoint. There is no expected impact beyond this except for efficiency gains.
Impact to hand-coders
For those of you coding your own, you can choose to use normal protoc, or our standard zipkin2 library. Our bundled SpanBytesEncoder.PROTO3 has no external dependencies. While this added some size, our jar is still less than 200K.
Zipkin 2.7
Zipkin 2.7 is maintenance focused. It deprecates custom servers, removes
Scribe from our default jar and aligns internals towards future upgrades.
Explain custom servers are unsupported via deprecation
Especially lately, we have had a large number of people having problems
with unnecessarily custom servers. Some are due to not knowing Sleuth's
stream server is obviated by our Rabbit MQ support. Some are due to blogs
which unfortunately recommend starting Zipkin in the IDE via a custom
server. Some are due to version drift when people change to Spring Boot 2.
As of Zipkin 2.7, the @EnableZipkinServer annotation is still available, but
includes the following notice:
Custom servers are possible, but not supported by the community. Please use
our default server build first. If you find something missing, please gitter us
about it before making a custom server.
If you decide to make a custom server, you accept responsibility for
troubleshooting your build or configuration problems, even if such problems are
a reaction to a change made by the OpenZipkin maintainers. In other words,
custom servers are possible, but not supported.
Removes Scribe from the default jar, as an optional module
The long since archived thrift-RPC transport Scribe is no longer in our exec
jar file. It is still available in the docker image. We removed this for reasons
including support concerns as the library we use hasn't had maintenance in two
years. If you are not using Docker, yet using Scribe see our README for more.
Aligning internals towards Spring Boot 2 upgrade
Zipkin's server is currently Spring Boot 1.5.x. Our cloud plugins for Amazon,
Azure and Google use a module layout removed in Spring Boot 2. To ready for a
future upgrade, @zeagord wrote our own layout factory, compatible with both
versions. Thanks for the help, Raja!
Other notes
- zipkin-zookeeper is now in the attic https://github.com/openzipkin-attic/zipkin-zookeeper
- @narayaruna fixed a glitch where in Elasticsearch we intended to index 256 characters not 255
- @narayaruna fixed a glitch where we did client side filtering in Elasticsearch when it wasn't necessary
- @Logic-32 fixed a bug where SEARCH_ENABLED=false didn't disable UI search controls
- empty RABBIT_URI properties are now ignored
Zipkin 2.6
Zipkin 2.6 adds "View Saved Trace" screen and makes the UI work through Kubernetes ingress controllers. As usual, the updates below are pushed to docker for all of our images at latest version, including the cloud ones: zipkin-aws, zipkin-azure and zipkin-gcp
View Saved Trace screen
We've had a myriad of requests, usually those supporting tracing sites, for an ability to view a saved trace. This has come in many forms, from trying to mutate TTL values, to proxying other servers, you name it. Lacking a perfect solution, through the help of @Logic-32 we have a pragmatic one: "View Saved Trace".
It is very simple, you click it and select a file

For example, if you saved an example json, you can see how the UI presents it.
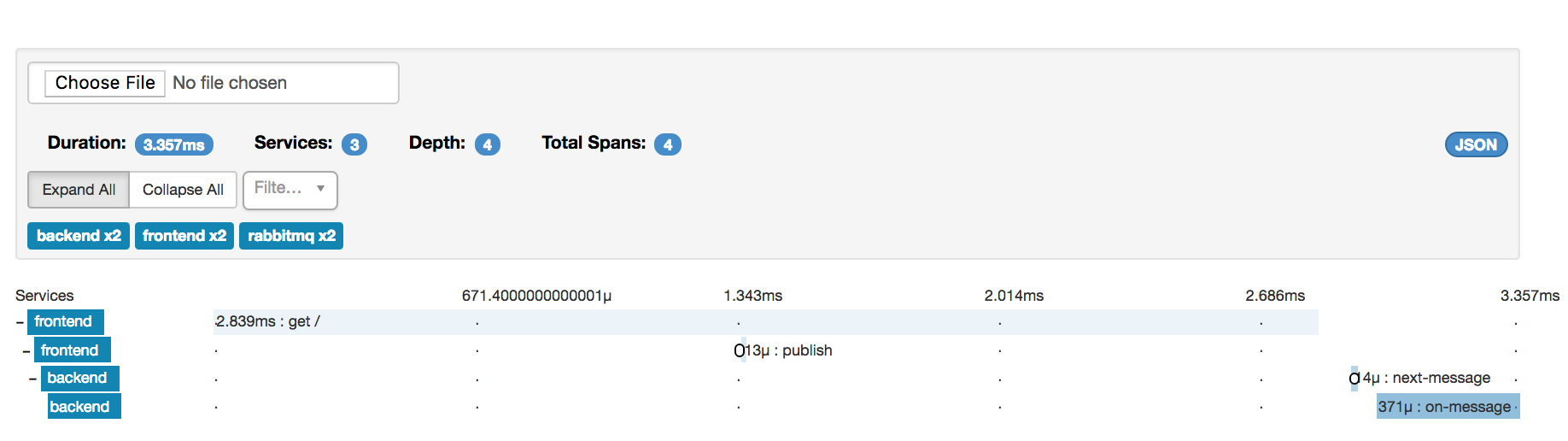
Who would use this? Support certainly will as this allows an easier way to get on the same page safely. For example, you can save trace json from an outage. Weeks or years later.. after the data expired.. simply open that file to revisit the topic. Internally, UI dev is easier as there's literally no remote dependency. For example, some motivation for this is testing towards the 10k span problem.
Why not integrate with S3, data retention policy override, or a remote cluster etc? @naoman helped with a remote zipkin approach. Eventhough it was viable, and good code, integration is very site and security policy specific. This made it too polarizing. It could be that one day there's a separate plugin or utility for aggregating "favorite traces", but at least now you can accomplish similar clicking JSON and saving it to your favorite (potentially cloud-backed) disk :)
Thanks very much to @Logic-32 for the code here, but also to @naoman who had an alternate solution leading to this.
Zipkin UI and Kubernetes ingress controller
Zipkin's UI works via client-side routing based on a path prefix '/zipkin/'. Via a reverse proxy and a replacement filter, you can change this. The nginx ingress of Kubernetes has limited configurability, so was missing the ability to inject the tag remapping depends on.
@abesto and @wdittmer-mp got to the bottom of this through some epic investigations, leading to Zoltan coding up support for ZIPKIN_UI_BASEPATH, a special hook to handle this case. Yeah.. sounds special case, but k8s is a popular deployment environment... this is not as niche as it sounds!
Anyway thanks again to Zoltan and Wilfred for getting this to work. Wilfred's shared his setup, which mixes together a bunch of friends like prometheus, grafana and kibana on a bastion host. Have a look!
Other recent things
- We now properly process dependency links regardless of B3 or AWS propagation. Thanks to @sokac for getting to the bottom of this
- @igorwwwwwwwwwwwwwwwwwwww fixed a UI glitch where custom dates weren't refreshed properly
- @zeagord adjusted config so that you can do
./zipkin.jarinstead ofjava -jar zipkin.jaruseful in service run configuration - zipkin core api jars now have Java 9 module entries
ES_DATE_SEPARATOR=is now permitted for indexes likeyyyyMMdd. Thanks @narayaruna for the suggestion- There are a number of tweaks to the span detail screen, mostly scrubbing "undefined:0" style glitches for partially defined endpoints.
Zipkin 2.5
Zipkin 2.5 formalizes the tag "http.route", used for metrics correlation and span naming conventions. It also presents zipkin-gcp (formerly known as stackdriver-zipkin) for continued progress towards Google Cloud Platform. Finally, it includes a number of updates you may not have noticed!
http.route tag
The "http.route", used for metrics correlation and span naming conventions. Here's the definition:
The route which a request matched or "" (empty string) if routing is supported,
but none matched. Ex "/objects/{objectId}". Often used as a span name when
known, with empty routes coercing to "not_found" or "redirected" based on
HTTP_STATUS_CODE("http.status_code").
Unlike HTTP_PATH("http.path"), this value is fixed cardinality, so is a safe
input to a span name function or a metrics dimension. Different formats are
possible. For example, the following are all valid route templates:
"/objects" "/objects/:objectId" "/objects/*"
A common use of http route is for an input to a span naming function. You'll notice that the following is intuitive to folks unfamiliar with specific frameworks:

Here's a partial list of zipkin instrumentation which currently support route-based naming. More will happen soon, so keep an eye open for updates!
Credits
The idea of an http template tag is not a new idea. Our thrift definition mentioned this for a couple years, as a better alternative to http.path for cardinality. @takezoe's play-zipkin-tracing has always had template-based span names. We don't introduce tags regularly, as it takes several months to formalize (this certainly did). Introducing "http.route" now is "right timed" as projects such as census, kamon and micrometer integrate stats and tracing with common keys. It was also right timed as we had overwhelming support from our community.
To that end, a lot of thanks go to our extended community for input. For example, @ivantopo from Kamon helped with technical mapping in the scala play framework, which reduced the time spent investigating and integrating. @rakyll named the tag, ensuring it is consistently labeled in census. @jkschneider from micrometer spent a large amount of effort bringing forth some naming considerations and technical impacts for metrics. For example, how to handle redirects. These were adopted in brave, the java tracer.
This is not to downplay input by zipkin regulars, such as @bplotnick @mikewrighton @jcchavezs @takezoe @devinsba @shakuzen @hyleung @basvanbeek, or zipkin newcomers like @spockz who took active roles in discussion or added instrumentation support.
zipkin-gcp (Google Cloud Platform)
Back in late 2016, the Google Stackdriver team released a tool called stackdriver-zipkin to allow existing Zipkin applications to choose their free cloud service as a storage option.
The stackdriver-zipkin project runs as an http proxy and is simple to use. Over time, users started to ask for more flexibility. For example, other transports that exist in Zipkin (like Kafka) or that only exist in GCP like Pub/Sub. Some wanted to embed a stackdriver reporter in their zipkin-enabled apps as opposed routing via to a proxy.
Between late 2016 and now, the OpenZipkin community has a process which allows such developments and exists for Azure and Amazon Web Services. Starting with Zipkin 2.5, stackdriver-zipkin migrates into the zipkin-gcp project which allows the community to maintain it in a fashion to meet these goals.
If you want to try Zipkin against Stackdriver, the easiest start is to share
your credentials with Zipkin's docker image.
$ docker run -d -p 9411:9411 \
-e STORAGE_TYPE=stackdriver \
-e GOOGLE_APPLICATION_CREDENTIALS=/root/.gcp/credentials.json \
-e STACKDRIVER_PROJECT_ID=your_project \
-v $HOME/.gcp:/root/.gcp:ro \
openzipkin/zipkin-gcpCredits
Thanks very much to the contributors of stackdriver-zipkin as they've done a stellar job in the last year plus. Special thanks to @mtwo for proxying the technicalities of migrating a google project into another org. Thanks to @bogdandrutu for a lot of technical support and releases leading up to the migration. Thanks to @anuraaga for a lot of recent work on the codebase and @denyska for not being timid about fixing difficult problems. Finally, thanks to @saturnism for the community work around Google and Zipkin. Ray's advice, patience and help are always appreciated, and his docs are great!
Notable recent updates
There have been notable improvements since the last release notes (Zipkin 2.4.5). Here's a roundup of highlights
- @michaelsembwever removed separate cassandra keyspace "zipkin2_udts" only used for UDT initialization.
- @shakuzen added RABBIT_URI to allow RabbitMQ configuration in environments like Cloud Foundry
- @ScienJus fixed slow api request when loading zipkin UI's home screen
overlapping calls to health check are no longer permitted. - @Logic-32 disabled the search screen when in "firehose mode" (SEARCH_ENABLED=false)
- @michaelsembwever made cassandra3 search operate even when SASI is disabled for annotationQuery (the biggest index)
- @xeraa fixes our docs for Kibana integration
- mysql now uses the correct index based on STRICT_TRACE_ID
- special shout-out to @mvallebr and @drolando for feedback and testing of our cassandra3 setup
Zipkin 2.4.5
Zipkin 2.4.5 improves performance of our core model types and sneaks in an experimental feature
- zipkin2 types now implement serializable directly to help with frameworks like Flink
- thanks to advice from @raphw our model types are more efficient (#1890)
- @michaelsembwever @drolando helped add an experimental feature which lowers storage pressure by disabling search. This feature will be explained more when finalized (#1876)
Do not use Zipkin 2.4.4 as it has a regression
Zipkin 2.4.4 had a stack overflow bug on debug spans which was fixed and released immediately as 2.4.5
Zipkin 2.4.3
Zipkin 2.4.3 includes a couple UI improvements, some asked for quite a while!
@basvanbeek removed redundant tags from the span detail screen (where client and server reported the same value)
@igorwwwwwwwwwwwwwwwwwwww polished up the layout of the search screen

Thanks for the continued help improving the UI!
Zipkin 2.4.2
Zipkin 2.4.2 is a grab-bag of help from a various contributors:
@hexchain helped identify and resolve glitches querying data with mixed-length trace IDs
@igorwwwwwwwwwwwwwwwwwwww put some time into the UI resulting in
- less jumpiness on "more info" button
- faster page load
- improve page rendering time
- less confusing yyyy-mm-dd date conventions
@gianarb and @drolando collaborated on our new Italian language support in the UI
Other small changes include better partitioning of the in-memory data store, and data conversion fix-ups.
It takes special people to help fix, add to or polish features they didn't write. We owe special thanks to community members who help with this sort of thing.