![]()

Tutorial, practical samples and other resources about Event Sourcing in .NET. See also my similar repositories for JVM and NodeJS.
- EventSourcing .NET
- 1. Event Sourcing
- 2. Videos
- 2.1. Practical Event Sourcing with Marten
- 2.2. Keep your streams short! Or how to model event-sourced systems efficiently
- 2.3. Let's build event store in one hour!
- 2.4. CQRS is Simpler than you think with C#11 & NET7
- 2.5. Practical Introduction to Event Sourcing with EventStoreDB
- 2.6. How to deal with privacy and GDPR in Event-Sourced systems
- 2.7 Let's build the worst Event Sourcing system!
- 2.8 The Light and The Dark Side of the Event-Driven Design
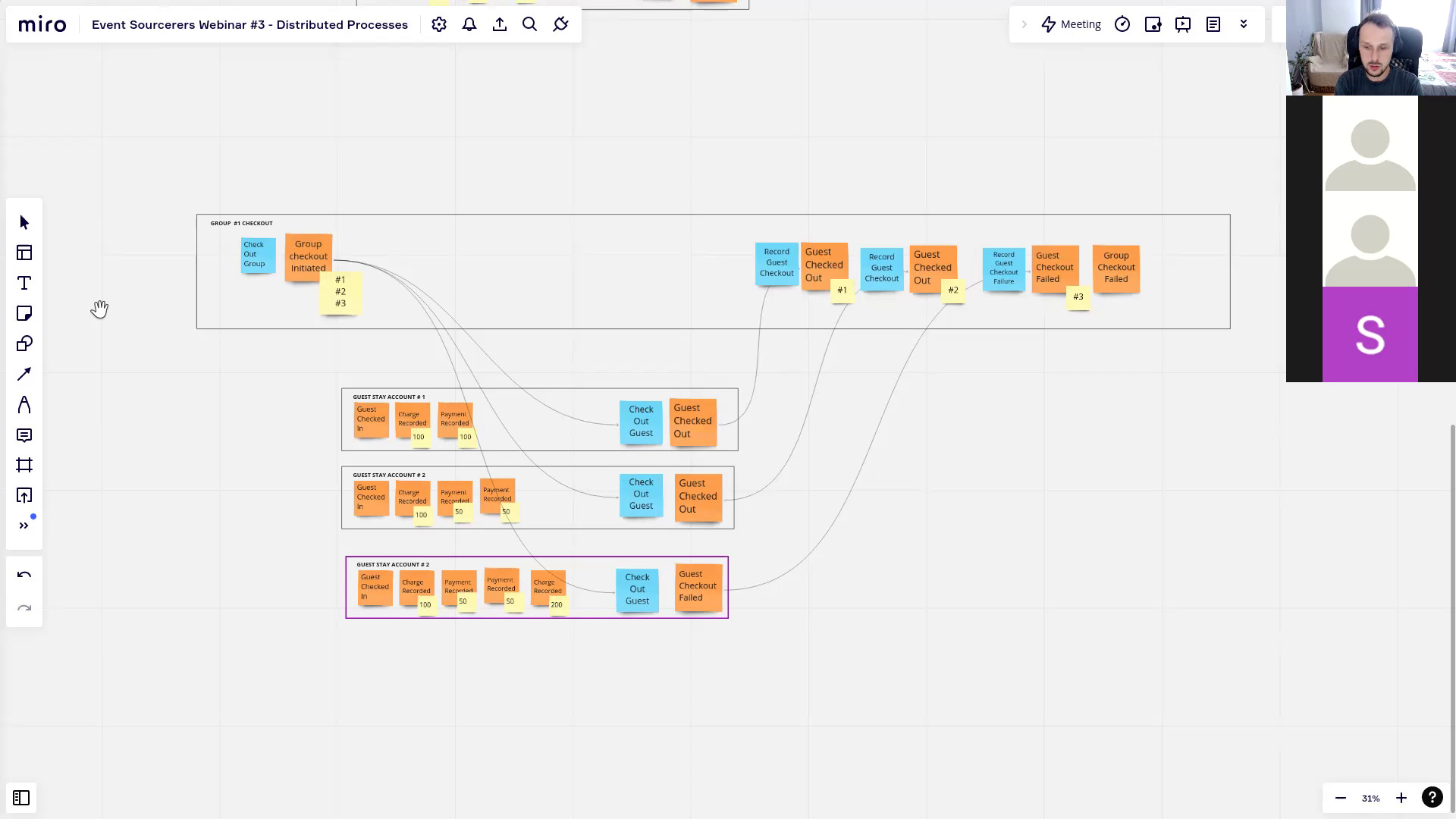
- 2.9 Implementing Distributed Processes
- 2.10 Conversation with Yves Lorphelin about CQRS
- 2.11. Never Lose Data Again - Event Sourcing to the Rescue!
- 3. Support
- 4. Prerequisites
- 5. Tools used
- 6. Samples
- 6.1 Pragmatic Event Sourcing With Marten
- 6.2 ECommerce with Marten
- 6.3 Simple EventSourcing with EventStoreDB
- 6.4 Implementing Distributed Processes
- 6.5 ECommerce with EventStoreDB
- 6.6 Warehouse
- 6.7 Warehouse Minimal API
- 6.8 Event Versioning
- 6.9 Event Pipelines
- 6.10 Meetings Management with Marten
- 6.11 Cinema Tickets Reservations with Marten
- 6.12 SmartHome IoT with Marten
- 7. Self-paced training Kits
- 8. Articles
- 9. Event Store - Marten
- 10. CQRS (Command Query Responsibility Separation)
- 11. NuGet packages to help you get started.
- 12. Other resources
- 12.1 Introduction
- 12.2 Event Sourcing on production
- 12.3 Projections
- 12.4 Snapshots
- 12.5 Versioning
- 12.6 Storage
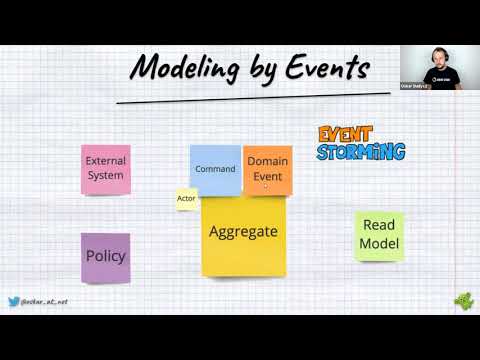
- 12.7 Design & Modeling
- 12.8 GDPR
- 12.9 Conflict Detection
- 12.10 Functional programming
- 12.12 Testing
- 12.13 CQRS
- 12.14 Tools
- 12.15 Event processing
- 12.16 Distributed processes
- 12.17 Domain Driven Design
- 12.18 Whitepapers
- 12.19 Event Sourcing Concerns
- 12.20 This is NOT Event Sourcing (but Event Streaming)
- 12.21 Architecture Weekly
- License
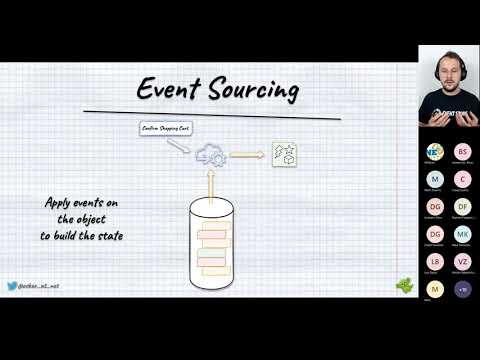
Event Sourcing is a design pattern in which results of business operations are stored as a series of events.
It is an alternative way to persist data. In contrast with state-oriented persistence that only keeps the latest version of the entity state, Event Sourcing stores each state change as a separate event.
Thanks to that, no business data is lost. Each operation results in the event stored in the database. That enables extended auditing and diagnostics capabilities (both technically and business-wise). What's more, as events contains the business context, it allows wide business analysis and reporting.
In this repository I'm showing different aspects and patterns around Event Sourcing from the basic to advanced practices.
Read more in my articles:
Events represent facts in the past. They carry information about something accomplished. It should be named in the past tense, e.g. "user added", "order confirmed". Events are not directed to a specific recipient - they're broadcasted information. It's like telling a story at a party. We hope that someone listens to us, but we may quickly realise that no one is paying attention.
Events:
- are immutable: "What has been seen, cannot be unseen".
- can be ignored but cannot be retracted (as you cannot change the past).
- can be interpreted differently. The basketball match result is a fact. Winning team fans will interpret it positively. Losing team fans - not so much.
Read more in my articles:
- 📝 What's the difference between a command and an event?
- 📝 Events should be as small as possible, right?
- 📝 Anti-patterns in event modelling - Property Sourcing
- 📝 Anti-patterns in event modelling - State Obsession
Events are logically grouped into streams. In Event Sourcing, streams are the representation of the entities. All the entity state mutations end up as the persisted events. Entity state is retrieved by reading all the stream events and applying them one by one in the order of appearance.
A stream should have a unique identifier representing the specific object. Each event has its own unique position within a stream. This position is usually represented by a numeric, incremental value. This number can be used to define the order of the events while retrieving the state. It can also be used to detect concurrency issues.
Technically events are messages.
They may be represented, e.g. in JSON, Binary, XML format. Besides the data, they usually contain:
- id: unique event identifier.
- type: name of the event, e.g. "invoice issued".
- stream id: object id for which event was registered (e.g. invoice id).
- stream position (also named version, order of occurrence, etc.): the number used to decide the order of the event's occurrence for the specific object (stream).
- timestamp: representing a time at which the event happened.
- other metadata like
correlation id,causation id, etc.
Sample event JSON can look like:
{
"id": "e44f813c-1a2f-4747-aed5-086805c6450e",
"type": "invoice-issued",
"streamId": "INV/2021/11/01",
"streamPosition": 1,
"timestamp": "2021-11-01T00:05:32.000Z",
"data":
{
"issuedTo": {
"name": "Oscar the Grouch",
"address": "123 Sesame Street"
},
"amount": 34.12,
"number": "INV/2021/11/01",
"issuedAt": "2021-11-01T00:05:32.000Z"
},
"metadata":
{
"correlationId": "1fecc92e-3197-4191-b929-bd306e1110a4",
"causationId": "c3cf07e8-9f2f-4c2d-a8e9-f8a612b4a7f1"
}
}Read more in my articles:
Event Sourcing is not related to any type of storage implementation. As long as it fulfills the assumptions, it can be implemented having any backing database (relational, document, etc.). The state has to be represented by the append-only log of events. The events are stored in chronological order, and new events are appended to the previous event. Event Stores are the databases' category explicitly designed for such purpose.
Read more in my articles:
- 📝 Let's build event store in one hour!
- 📝 What if I told you that Relational Databases are in fact Event Stores?
In Event Sourcing, the state is stored in events. Events are logically grouped into streams. Streams can be thought of as the entities' representation. Traditionally (e.g. in relational or document approach), each entity is stored as a separate record.
| Id | IssuerName | IssuerAddress | Amount | Number | IssuedAt |
|---|---|---|---|---|---|
| e44f813c | Oscar the Grouch | 123 Sesame Street | 34.12 | INV/2021/11/01 | 2021-11-01 |
In Event Sourcing, the entity is stored as the series of events that happened for this specific object, e.g. InvoiceInitiated, InvoiceIssued, InvoiceSent.
[
{
"id": "e44f813c-1a2f-4747-aed5-086805c6450e",
"type": "invoice-initiated",
"streamId": "INV/2021/11/01",
"streamPosition": 1,
"timestamp": "2021-11-01T00:05:32.000Z",
"data":
{
"issuer": {
"name": "Oscar the Grouch",
"address": "123 Sesame Street",
},
"amount": 34.12,
"number": "INV/2021/11/01",
"initiatedAt": "2021-11-01T00:05:32.000Z"
}
},
{
"id": "5421d67d-d0fe-4c4c-b232-ff284810fb59",
"type": "invoice-issued",
"streamId": "INV/2021/11/01",
"streamPosition": 2,
"timestamp": "2021-11-01T00:11:32.000Z",
"data":
{
"issuedTo": "Cookie Monster",
"issuedAt": "2021-11-01T00:11:32.000Z"
}
},
{
"id": "637cfe0f-ed38-4595-8b17-2534cc706abf",
"type": "invoice-sent",
"streamId": "INV/2021/11/01",
"streamPosition": 3,
"timestamp": "2021-11-01T00:12:01.000Z",
"data":
{
"sentVia": "email",
"sentAt": "2021-11-01T00:12:01.000Z"
}
}
]All of those events share the stream id ("streamId": "INV/2021/11/01"), and have incremented stream positions.
In Event Sourcing each entity is represented by its stream: the sequence of events correlated by the stream id ordered by stream position.
To get the current state of an entity we need to perform the stream aggregation process. We're translating the set of events into a single entity. This can be done with the following steps:
- Read all events for the specific stream.
- Order them ascending in the order of appearance (by the event's stream position).
- Construct the empty object of the entity type (e.g. with default constructor).
- Apply each event on the entity.
This process is called also stream aggregation or state rehydration.
We could implement that as:
public record Person(
string Name,
string Address
);
public record InvoiceInitiated(
double Amount,
string Number,
Person IssuedTo,
DateTime InitiatedAt
);
public record InvoiceIssued(
string IssuedBy,
DateTime IssuedAt
);
public enum InvoiceSendMethod
{
Email,
Post
}
public record InvoiceSent(
InvoiceSendMethod SentVia,
DateTime SentAt
);
public enum InvoiceStatus
{
Initiated = 1,
Issued = 2,
Sent = 3
}
public class Invoice
{
public string Id { get;set; }
public double Amount { get; private set; }
public string Number { get; private set; }
public InvoiceStatus Status { get; private set; }
public Person IssuedTo { get; private set; }
public DateTime InitiatedAt { get; private set; }
public string IssuedBy { get; private set; }
public DateTime IssuedAt { get; private set; }
public InvoiceSendMethod SentVia { get; private set; }
public DateTime SentAt { get; private set; }
public void Evolve(object @event)
{
switch (@event)
{
case InvoiceInitiated invoiceInitiated:
Apply(invoiceInitiated);
break;
case InvoiceIssued invoiceIssued:
Apply(invoiceIssued);
break;
case InvoiceSent invoiceSent:
Apply(invoiceSent);
break;
}
}
private void Apply(InvoiceInitiated @event)
{
Id = @event.Number;
Amount = @event.Amount;
Number = @event.Number;
IssuedTo = @event.IssuedTo;
InitiatedAt = @event.InitiatedAt;
Status = InvoiceStatus.Initiated;
}
private void Apply(InvoiceIssued @event)
{
IssuedBy = @event.IssuedBy;
IssuedAt = @event.IssuedAt;
Status = InvoiceStatus.Issued;
}
private void Apply(InvoiceSent @event)
{
SentVia = @event.SentVia;
SentAt = @event.SentAt;
Status = InvoiceStatus.Sent;
}
}and use it as:
var invoiceInitiated = new InvoiceInitiated(
34.12,
"INV/2021/11/01",
new Person("Oscar the Grouch", "123 Sesame Street"),
DateTime.UtcNow
);
var invoiceIssued = new InvoiceIssued(
"Cookie Monster",
DateTime.UtcNow
);
var invoiceSent = new InvoiceSent(
InvoiceSendMethod.Email,
DateTime.UtcNow
);
// 1,2. Get all events and sort them in the order of appearance
var events = new object[] {invoiceInitiated, invoiceIssued, invoiceSent};
// 3. Construct empty Invoice object
var invoice = new Invoice();
// 4. Apply each event on the entity.
foreach (var @event in events)
{
invoice.Evolve(@event);
}and generalise this into Aggregate base class:
public abstract class Aggregate<T>
{
public T Id { get; protected set; }
protected Aggregate() { }
public virtual void Evolve(object @event) { }
}The biggest advantage of "online" stream aggregation is that it always uses the most recent business logic. So after the change in the apply method, it's automatically reflected on the next run. If events data is fine, then it's not needed to do any migration or updates.
In Marten Evolve method is not needed. Marten uses naming convention and call the Apply method internally. It has to:
- have single parameter with event object,
- have
voidtype as the result.
See samples:
Read more in my article:
- 📝 How to get the current entity state from events?
- 📝 Should you throw an exception when rebuilding the state from events?
Strongly typed ids (or, in general, a proper type system) can make your code more predictable. It reduces the chance of trivial mistakes, like accidentally changing parameters order of the same primitive type.
So for such code:
var reservationId = "RES/01";
var seatId = "SEAT/22";
var customerId = "CUS/291";
var reservation = new Reservation(
reservationId,
seatId,
customerId
);the compiler won't catch if you switch reservationId with seatId.
If you use strongly typed ids, then compile will catch that issue:
var reservationId = new ReservationId("RES/01");
var seatId = new SeatId("SEAT/22");
var customerId = new CustomerId("CUS/291");
var reservation = new Reservation(
reservationId,
seatId,
customerId
);They're not ideal, as they're usually not playing well with the storage engines. Typical issues are: serialisation, Linq queries, etc. For some cases they may be just overkill. You need to pick your poison.
To reduce tedious, copy/paste code, it's worth defining a strongly-typed id base class, like:
public class StronglyTypedValue<T>: IEquatable<StronglyTypedValue<T>> where T: IComparable<T>
{
public T Value { get; }
public StronglyTypedValue(T value)
{
Value = value;
}
public bool Equals(StronglyTypedValue<T>? other)
{
if (ReferenceEquals(null, other)) return false;
if (ReferenceEquals(this, other)) return true;
return EqualityComparer<T>.Default.Equals(Value, other.Value);
}
public override bool Equals(object? obj)
{
if (ReferenceEquals(null, obj)) return false;
if (ReferenceEquals(this, obj)) return true;
if (obj.GetType() != this.GetType()) return false;
return Equals((StronglyTypedValue<T>)obj);
}
public override int GetHashCode()
{
return EqualityComparer<T>.Default.GetHashCode(Value);
}
public static bool operator ==(StronglyTypedValue<T>? left, StronglyTypedValue<T>? right)
{
return Equals(left, right);
}
public static bool operator !=(StronglyTypedValue<T>? left, StronglyTypedValue<T>? right)
{
return !Equals(left, right);
}
}Then you can define specific id class as:
public class ReservationId: StronglyTypedValue<Guid>
{
public ReservationId(Guid value) : base(value)
{
}
}You can even add additional rules:
public class ReservationNumber: StronglyTypedValue<string>
{
public ReservationNumber(string value) : base(value)
{
if (string.IsNullOrEmpty(value) || !value.StartsWith("RES/") || value.Length <= 4)
throw new ArgumentOutOfRangeException(nameof(value));
}
}The base class working with Marten, can be defined as:
public abstract class Aggregate<TKey, T>
where TKey: StronglyTypedValue<T>
where T : IComparable<T>
{
public TKey Id { get; set; } = default!;
[Identity]
public T AggregateId {
get => Id.Value;
set {}
}
public int Version { get; protected set; }
[JsonIgnore] private readonly Queue<object> uncommittedEvents = new();
public object[] DequeueUncommittedEvents()
{
var dequeuedEvents = uncommittedEvents.ToArray();
uncommittedEvents.Clear();
return dequeuedEvents;
}
protected void Enqueue(object @event)
{
uncommittedEvents.Enqueue(@event);
}
}Marten requires the id with public setter and getter of string or Guid. We used the trick and added AggregateId with a strongly-typed backing field. We also informed Marten of the Identity attribute to use this field in its internals.
Example aggregate can look like:
public class Reservation : Aggregate<ReservationId, Guid>
{
public CustomerId CustomerId { get; private set; } = default!;
public SeatId SeatId { get; private set; } = default!;
public ReservationNumber Number { get; private set; } = default!;
public ReservationStatus Status { get; private set; }
public static Reservation CreateTentative(
SeatId seatId,
CustomerId customerId)
{
return new Reservation(
new ReservationId(Guid.NewGuid()),
seatId,
customerId,
new ReservationNumber(Guid.NewGuid().ToString())
);
}
// (...)
}See the full sample here.
Read more in the article:
- 📝 Using strongly-typed identifiers with Marten
- 📝 Immutable Value Objects are simpler and more useful than you think!







2.10 Conversation with Yves Lorphelin about CQRS

Feel free to create an issue if you have any questions or request for more explanation or samples. I also take Pull Requests!
💖 If this repository helped you - I'd be more than happy if you join the group of my official supporters at:
⭐ Star on GitHub or sharing with your friends will also help!
For running the Event Store examples you need to have:
- .NET 6 installed - https://dotnet.microsoft.com/download/dotnet/6.0
- Docker installed. Then going to the
dockerfolder and running:
docker compose --profile all up
More information about using .NET, WebApi and Docker you can find in my other tutorials: WebApi with .NET
- Marten - Event Store and Read Models
- EventStoreDB - Event Store
- Kafka - External Durable Message Bus to integrate services
- ElasticSearch - Read Models
See also fully working, real-world samples of Event Sourcing and CQRS applications in Samples folder.
Samples are using CQRS architecture. They're sliced based on the business modules and operations. Read more about the assumptions in "How to slice the codebase effectively?".
- Simplest CQRS and Event Sourcing flow using Minimal API,
- Cutting the number of layers and boilerplate complex code to bare minimum,
- Using all Marten helpers like
WriteToAggregate,AggregateStreamto simplify the processing, - Examples of all the typical Marten's projections,
- Example of how and where to use C# Records, Nullable Reference Types, etc,
- No Aggregates. Commands are handled in the domain service as pure functions.
- typical Event Sourcing and CQRS flow,
- DDD using Aggregates,
- microservices example,
- stores events to Marten,
- distributed processes coordinated by Saga (Order Saga),
- Kafka as a messaging platform to integrate microservices,
- example of the case when some services are event-sourced (Carts, Orders, Payments) and some are not (Shipments using EntityFramework as ORM)
- typical Event Sourcing and CQRS flow,
- functional composition, no aggregates, just data and functions,
- stores events to EventStoreDB,
- Builds read models using Subscription to
$all, - Read models are stored as Postgres tables using EntityFramework.
- orchestrate and coordinate business workflow spanning across multiple aggregates using Saga pattern,
- handle distributed processing both for asynchronous commands scheduling and events publishing,
- getting at-least-once delivery guarantee,
- implementing command store and outbox pattern on top of Marten and EventStoreDB,
- unit testing aggregates and Saga with a little help from Ogooreck,
- testing asynchronous code.
- typical Event Sourcing and CQRS flow,
- DDD using Aggregates,
- stores events to EventStoreDB,
- Builds read models using Subscription to
$all. - Read models are stored as Marten documents.
6.6 Warehouse
- simplest CQRS flow using .NET Endpoints,
- example of how and where to use C# Records, Nullable Reference Types, etc,
- No Event Sourcing! Using Entity Framework to show that CQRS is not bounded to Event Sourcing or any type of storage,
- No Aggregates! CQRS do not need DDD. Business logic can be handled in handlers.
Variation of the previous example, but:
- using Minimal API,
- example how to inject handlers in MediatR like style to decouple API from handlers.
- 📝 Read more CQRS is simpler than you think with .NET 6 and C# 10
6.8 Event Versioning
Shows how to handle basic event schema versioning scenarios using event and stream transformations (e.g. upcasting):
- Simple mapping
- Upcasting
- Downcasters
- Events Transformations
- Stream Transformation
- Summary
- 📝 Simple patterns for events schema versioning
6.9 Event Pipelines
Shows how to compose event handlers in the processing pipelines to:
- filter events,
- transform them,
- NOT requiring marker interfaces for events,
- NOT requiring marker interfaces for handlers,
- enables composition through regular functions,
- allows using interfaces and classes if you want to,
- can be used with Dependency Injection, but also without through builder,
- integrates with MediatR if you want to.
- 📝 Read more How to build a simple event pipeline
- typical Event Sourcing and CQRS flow,
- DDD using Aggregates,
- microservices example,
- stores events to Marten,
- Kafka as a messaging platform to integrate microservices,
- read models handled in separate microservice and stored to other database (ElasticSearch)
- typical Event Sourcing and CQRS flow,
- DDD using Aggregates,
- stores events to Marten.
- typical Event Sourcing and CQRS flow,
- DDD using Aggregates,
- stores events to Marten,
- asynchronous projections rebuild using AsyncDaemon feature.
I prepared the self-paced training Kits for the Event Sourcing. See more in the Workshop description.
Event Sourcing is perceived as a complex pattern. Some believe that it's like Nessie, everyone's heard about it, but rarely seen it. In fact, Event Sourcing is a pretty practical and straightforward concept. It helps build predictable applications closer to business. Nowadays, storage is cheap, and information is priceless. In Event Sourcing, no data is lost.
The workshop aims to build the knowledge of the general concept and its related patterns for the participants. The acquired knowledge will allow for the conscious design of architectural solutions and the analysis of associated risks.
The emphasis will be on a pragmatic understanding of architectures and applying it in practice using Marten and EventStoreDB.
You can do the workshop as a self-paced kit. That should give you a good foundation for starting your journey with Event Sourcing and learning tools like Marten and EventStoreDB. If you'd like to get full coverage with all nuances of the private workshop, feel free to contact me via email.
- Events definition.
- Getting State from events.
- Appending Events:
- Getting State from events
- Business logic:
- Optimistic Concurrency:
- Projections:
It teaches the event store basics by showing how to build your Event Store on top of Relational Database. It starts with the tables setup, goes through appending events, aggregations, projections, snapshots, and finishes with the Marten basics.
- Streams Table
- Events Table
- Appending Events
- Optimistic Concurrency Handling
- Event Store Methods
- Stream Aggregation
- Time Travelling
- Aggregate and Repositories
- Snapshots
- Projections
- Projections With Marten
Read also more on the Event Sourcing and CQRS topics in my blog posts:
- 📝 Introduction to Event Sourcing - Self Paced Kit
- 📝 Never Lose Data Again - Event Sourcing to the Rescue!
- 📝 Event stores are key-value databases, and why that matters
- 📝 What's the difference between a command and an event?
- 📝 Event Streaming is not Event Sourcing!
- 📝 Don't let Event-Driven Architecture buzzwords fool you
- 📝 Events should be as small as possible, right?
- 📝 How to get the current entity state from events?
- 📝 Should you throw an exception when rebuilding the state from events?
- 📝 Let's build event store in one hour!
- 📝 How to effectively compose your business logic
- 📝 Slim your aggregates with Event Sourcing!
- 📝 Testing business logic in Event Sourcing, and beyond!
- 📝 Writing and testing business logic in F#
- 📝 How to ensure uniqueness in Event Sourcing
- 📝 Ensuring uniqueness in Marten event store
- 📝 Anti-patterns in event modelling - Property Sourcing
- 📝 Anti-patterns in event modelling - State Obsession
- 📝 Why a bank account is not the best example of Event Sourcing?
- 📝 When not to use Event Sourcing?
- 📝 CQRS facts and myths explained
- 📝 How to slice the codebase effectively?
- 📝 Generic does not mean Simple?
- 📝 Can command return a value?
- 📝 CQRS is simpler than you think with .NET 6 and C# 10
- 📝 Union types in C#
- 📝 How to register all CQRS handlers by convention
- 📝 How to use ETag header for optimistic concurrency
- 📝 Guide to Projections and Read Models in Event-Driven Architecture
- 📝 Event-driven projections in Marten explained
- 📝 Projecting Marten events to Elasticsearch
- 📝 Publishing read model changes from Marten
- 📝 Integrating Marten with other systems
- 📝 Persistent vs catch-up, EventStoreDB subscriptions in action
- 📝 How to create projections of events for nested object structures?
- 📝 How to scale projections in the event-driven systems?
- 📝 Dealing with Eventual Consistency and Idempotency in MongoDB projections
- 📝 How to test event-driven projections
- 📝 Long-polling, how to make our async API synchronous
- 📝 A simple trick for idempotency handling in the Elastic Search read model
- 📝 How to do snapshots in Marten?
- 📝 How events can help in making the state-based approach efficient
- 📝 How to build a simple event pipeline
- 📝 How to handle multiple commands in the same transaction
- 📝 Mapping event type by convention
- 📝 Explicit events serialisation in Event Sourcing
- 📝 How to (not) do the events versioning?
- 📝 Event Versioning with Marten
- 📝 Simple patterns for events schema versioning
- 📝 Set up OpenTelemetry with Event Sourcing and Marten
- 📝 Immutable Value Objects are simpler and more useful than you think!
- 📝 Explicit validation in C# just got simpler!
- 📝 Notes about C# records and Nullable Reference Types
- 📝 Using strongly-typed identifiers with Marten
- 📝 How using events helps in a teams' autonomy
- 📝 What texting your Ex has to do with Event-Driven Design?
- 📝 What if I told you that Relational Databases are in fact Event Stores?
- 📝 Optimistic concurrency for pessimistic times
- 📝 Outbox, Inbox patterns and delivery guarantees explained
- 📝 Saga and Process Manager - distributed processes in practice
- 📝 Event-driven distributed processes by example
- 📝 Testing asynchronous processes with a little help from .NET Channels
- Creating event store
- Event Stream - is a representation of the entity in event sourcing. It's a set of events that happened for the entity with the exact id. Stream id should be unique, can have different types but usually is a Guid.
- Stream starting - stream should be always started with a unique id. Marten provides three ways of starting the stream:
- calling StartStream method with a stream id
var streamId = Guid.NewGuid(); documentSession.Events.StartStream<IssuesList>(streamId);
- calling StartStream method with a set of events
var @event = new IssueCreated { IssueId = Guid.NewGuid(), Description = "Description" }; var streamId = documentSession.Events.StartStream<IssuesList>(@event);
- just appending events with a stream id
var @event = new IssueCreated { IssueId = Guid.NewGuid(), Description = "Description" }; var streamId = Guid.NewGuid(); documentSession.Events.Append(streamId, @event);
- calling StartStream method with a stream id
- Stream loading - all events that were placed on the event store should be possible to load them back. Marten allows to:
- get list of event by calling FetchStream method with a stream id
var eventsList = documentSession.Events.FetchStream(streamId);
- geting one event by its id
var @event = documentSession.Events.Load<IssueCreated>(eventId);
- get list of event by calling FetchStream method with a stream id
- Stream loading from exact state - all events that were placed on the event store should be possible to load them back. Marten allows to get stream from exact state by:
- timestamp (has to be in UTC)
var dateTime = new DateTime(2017, 1, 11); var events = documentSession.Events.FetchStream(streamId, timestamp: dateTime);
- version number
var versionNumber = 3; var events = documentSession.Events.FetchStream(streamId, version: versionNumber);
- timestamp (has to be in UTC)
- Stream starting - stream should be always started with a unique id. Marten provides three ways of starting the stream:
- Event stream aggregation - events that were stored can be aggregated to form the entity once again. During the aggregation, process events are taken by the stream id and then replayed event by event (so eg. NewTaskAdded, DescriptionOfTaskChanged, TaskRemoved). At first, an empty entity instance is being created (by calling default constructor). Then events based on the order of appearance are being applied on the entity instance by calling proper Apply methods.
- Online Aggregation - online aggregation is a process when entity instance is being constructed on the fly from events. Events are taken from the database and then aggregation is being done. The biggest advantage of online aggregation is that it always gets the most recent business logic. So after the change, it's automatically reflected and it's not needed to do any migration or updates.
- Inline Aggregation (Snapshot) - inline aggregation happens when we take the snapshot of the entity from the DB. In that case, it's not needed to get all events. Marten stores the snapshot as a document. This is good for performance reasons because only one record is being materialized. The con of using inline aggregation is that after business logic has changed records need to be reaggregated.
- Reaggregation - one of the biggest advantages of the event sourcing is flexibility to business logic updates. It's not needed to perform complex migration. For online aggregation it's not needed to perform reaggregation - it's being made always automatically. The inline aggregation needs to be reaggregated. It can be done by performing online aggregation on all stream events and storing the result as a snapshot.
- reaggregation of inline snapshot with Marten
var onlineAggregation = documentSession.Events.AggregateStream<TEntity>(streamId); documentSession.Store<TEntity>(onlineAggregation); documentSession.SaveChanges();
- reaggregation of inline snapshot with Marten
- Event transformations
- Events projection
- Multitenancy per schema
I gathered and generalized all of the practices used in this tutorial/samples in Nuget Packages maintained by me GoldenEye Framework. See more in:
-
GoldenEye DDD package - it provides a set of base and bootstrap classes that helps you to reduce boilerplate code and help you focus on writing business code. You can find all classes like Commands/Queries/Event handlers and many more. To use it run:
dotnet add package GoldenEye -
GoldenEye Marten package - contains helpers, and abstractions to use Marten as document/event store. Gives you abstractions like repositories etc. To use it run:
dotnet add package GoldenEye.Marten
- 📝 Event Store - A Beginner's Guide to Event Sourcing
- 🎞 Greg Young - CQRS & Event Sourcing
- 📰 Lorenzo Nicora - A visual introduction to event sourcing and cqrs
- 🎞 Mathew McLoughlin - An Introduction to CQRS and Event Sourcing Patterns
- 🎞 Emily Stamey - Hey Boss, Event Sourcing Could Fix That!
- 🎞 Derek Comartin - Event Sourcing Example & Explained in plain English
- 🎞 Duncan Jones - Introduction to event sourcing and CQRS
- 🎞 Roman Sachse - Event Sourcing - Do it yourself series
- 📝 Jay Kreps - Why local state is a fundamental primitive in stream processing
- 📝 Jay Kreps - The Log: What every software engineer should know about real-time data's unifying abstraction
- 🎞 Duncan Jones - Event Sourcing and CQRS on Azure serverless functions
- 📝 Christian Stettler - Domain Events vs. Event Sourcing
- 🎞 Martin Fowler - The Many Meanings of Event-Driven Architecture
- 📝 Martin Fowler - Event Sourcing
- 📝 Dennis Doomen - 16 design guidelines for successful Event Sourcing
- 🎞 Martin Kleppmann - Event Sourcing and Stream Processing at Scale
- 📝 Dennis Doomen - The Good, The Bad and the Ugly of Event Sourcing
- 🎞 Alexey Zimarev - DDD, Event Sourcing and Actors
- 🎞 Thomas Bøgh Fangel - Event Sourcing: Traceability, Consistency, Correctness
- 📝 Joseph Choe - Event Sourcing, Part 1: User Registration
- 🎞 Steven Van Beelen - Intro to Event-Driven Microservices using DDD, CQRS & Event sourcing
- 📝 Yves Lorphelin - The Inevitable Event-Centric Book
- 📝 Microsoft - Exploring CQRS and Event Sourcing
- 🎞 Alexey Zimarev - Event Sourcing in Production
- 📝 Leo Gorodinski - Scaling Event-Sourcing at Jet
- 📝 EventStoreDB - Customers' case studies
- 🎞 P. Avery, R. Reta - Scaling Event Sourcing for Netflix Downloads
- 📝 Netflix - Scaling Event Sourcing for Netflix Downloads, Episode 1
- 📝 Netflix - Scaling Event Sourcing for Netflix Downloads, Episode 2
- 📝 M. Overeem, M. Spoor, S. Jansen, S. Brinkkemper - An Empirical Characterization of Event Sourced Systems and Their Schema Evolution -- Lessons from Industry
- 🎞 Michiel Overeem - Event Sourcing after launch
- 🎞 Greg Young - A Decade of DDD, CQRS, Event Sourcing
- 📝 M. Kadijk, J. Taal - The beautiful headache called event sourcing
- 📝 Thomas Weiss - Planet-scale event sourcing with Azure Cosmos DB
- 🎞 D. Kuzenski, N. Piani - Beyond APIs: Re-architected System Integrations as Event Sourced
- 🎞 Greg Young - Why Event Sourced Systems Fail
- 🎞 Joris Kuipers - Day 2 problems in CQRS and event sourcing
- 🎞 Kacper Gunia - War Story: How a Large Corporation Used DDD to Replace a Loyalty System
- 🎞 Vladik Khononov - The Dark Side of Events
- 📝 Pedro Costa - Migrating to Microservices and Event-Sourcing: the Dos and Dont's
- 🎞 Dennis Doomen - An Event Sourcing Retrospective - The Good, The Bad and the Ugly
- 🎞 David Schmitz - Event Sourcing You are doing it wrong
- 📝 Dennis Doomen - A recipe for gradually migrating from CRUD to Event Sourcing
- 🎞 Nat Pryce - Mistakes made adopting event sourcing (and how we recovered)
- 📝 Alexey Zimarev - Projections in Event Sourcing
- 🎞 Derek Comartin - Projections in Event Sourcing: Build ANY model you want!
- 🎞 Alexey Zimarev - Understanding read models
- 📝 Kacper Gunia - Event Sourcing: Projections
- 📝 Kacper Gunia - Event Sourcing Projections patterns: Deduplication strategies
- 📝 Kacper Gunia - Event Sourcing Projections patterns: Consumer scaling
- 📝 Kacper Gunia - Event Sourcing Projections patterns: Side effect handling
- 📝 Kacper Gunia - Event Sourcing patterns: Replay side effect handling
- 📝 Anton Stöckl - Live Projections for Read Models with Event Sourcing and CQRS
- 📝 Kacper Gunia - Event Sourcing: Snapshotting
- 🎞 Derek Comartin - Event Sourcing: Rehydrating Aggregates with Snapshots
- 📝 Greg Young - Versioning in an Event Sourced System
- 📝 Kacper Gunia - Event Sourcing: Snapshotting
- 📝 M. Overeem, M. Spoor - The dark side of event sourcing: Managing data conversion
- 📝 Savvas Kleanthous - Event immutability and dealing with change
- 📝 Versioning in an Event Sourced System
- 📝 Greg Young - Building an Event Storage
- 📝 Yves Lorphelin - Requirements for the storage of events,
- 📝 Anton Stöckl - Essential features of an Event Store for Event Sourcing
- 📝 Adam Warski - Implementing event sourcing using a relational database
- 🎞 Greg Young - How an EventStore actually works
- 🎞 Andrii Litvinov - Event driven systems backed by MongoDB
- 📝 Dave Remy - Turning the database inside out with Event Store
- 📝 AWS Architecture Blog - How The Mill Adventure Implemented Event Sourcing at Scale Using DynamoDB
- 🎞 Sander Molenkamp: Practical CQRS and Event Sourcing on Azure
- 📝 Mathias Verraes - DDD and Messaging Architectures
- 📝 David Boike - Putting your events on a diet
- 🎞 Thomas Pierrain - As Time Goes By… (a Bi-temporal Event Sourcing story)
- 🎞 Thomas Ploch - The One Question To Haunt Everyone: What is a DDD Aggregate?
- 📝 Vaughn Vernon - Effective Aggregate Design Part I: Modeling a Single Aggregate
- 🎞 Derek Comartin - Aggregate (Root) Design: Separate Behavior & Data for Persistence
- 🎞 Mauro Servienti - All our aggregates are wrong
- 📝 Microsoft - Domain events: design and implementation
- 📝 Event Storming
- 📝 Event Modeling
- 📝 Wojciech Suwała - Building Microservices On .NET Core – Part 5 Marten An Ideal Repository For Your Domain Aggregates
- 📝 Michiel Rook - Forget me please? Event sourcing and the GDPR
- 📝 Michiel Rook - Event sourcing and the GDPR: a follow-up
- 📝 Johan Sydseter - GDPR compliant event sourcing with HashiCorp Vault
- 📝 Diego Martin - Protecting Sensitive Data in Event-Sourced Systems with Crypto Shredding
- 🎞 Bram Leenders - Scalable User Privacy: Crypto Shredding at Spotify
- 🎞 Stuart Herbert - Event Sourcing and GDPR: When Immutability Meets Reality
- 🎞 Masih Derkani - GDPR Compliance: Transparent Handing of Personally Identifiable Information in Event-Driven Systems
- 🎞 James Geall - Conflict Detection and Resolution in an EventSourced System
- 🎞 Lightbend - Data modelling for Replicated Event Sourcing
- 📰 Bartosz Sypytkowski - Collaborative Event Sourcing
- 📝 Greg Young - CQRS
- 📝 Jimmy Bogard - CQRS and REST: the perfect match
- 📝 Mark Seemann - CQS versus server-generated IDs
- 📝 Julie Lerman - Data Points - CQRS and EF Data Models
- 📝 Marco Bürckel - Some thoughts on using CQRS without Event Sourcing
- 📝 Bertrand Meyer - Eiffel: a language for software engineering (CQRS introduced)
- 🎞 Udi Dahan - CQRS – but different
- 📝 Greg Young - CQRS, Task Based UIs, Event Sourcing agh!
- 🛠️ Marten - .NET Transactional Document DB and Event Store on PostgreSQL
- 🛠️ EventStoreDB - The stream database built for Event Sourcing
- 🛠️ GoldenEye - The CQRS flavoured framework that will speed up your WebAPI and Microservices development
- 🛠️ Eventuous - Event Sourcing for .NET
- 🛠️ SQLStreamStore - Stream Store library targeting RDBMS based implementations for .NET
- 🛠️ Equinox - .NET Event Sourcing library with CosmosDB, EventStoreDB, SqlStreamStore and integration test backends
- 📝 Kamil Grzybek - The Outbox Pattern
- 🎞 Dev Mentors - Inbox & Outbox pattern - transactional message processing
- 📝 Jeremy D. Miller - Jasper's "Outbox" Pattern Support
- 📝 Gunnar Morling - Reliable Microservices Data Exchange With the Outbox Pattern
- 📝 Microsoft - Asynchronous message-based communication
- 📝 NServiceBus - Outbox
- 📝 Alvaro Herrera - Implement SKIP LOCKED for row-level locks
- 📝 Héctor García-Molina, Kenneth Salem - Sagas
- 🎞 Caitie McCaffrey - Applying the Saga Pattern
- 🎞 Chris Condron - Process Managers Made Simple
- 🎞 Martin Schimak - Know the Flow! Events, Commands & Long-Running Services
- 📝 Martin Schimak - Aggregates and Sagas are Processes
- 📝 Martin Schimak - Tackling Complex Event Flows
- 📝 Jean-Philippe Dutrève - Messaging Patterns : Flow, SAGA, Messaging Gateway and Observability With RabbitMQ Exchange to Exchange Bindings
- 🎞 Udi Dahan - If (domain logic) then CQRS or Saga?
- 🎞 Gregor Hohpe - Starbucks Does Not Use Two-Phase Commit
- 🎞 Derek ComartinDo you need a Distributed Transaction? Working through a Design Problem
- 📝 Thanh Le - What is SAGA Pattern and How important is it?
- 📝 Jimmy Bogard - Life Beyond Distributed Transactions: An Apostate's Implementation - Relational Resources
- 📝 Microsoft - A Saga on Sagas
- 📝 Microsoft - Design Patterns - Saga distributed transactions pattern
- 📝 Microsoft - Design Patterns - Choreography
- 🎞 Chris Richardson - Using sagas to maintain data consistency in a microservice architecture
- 📝 NServiceBus - Sagas
- 📝 NServiceBus sagas: Integrations
- 📝 Denis Rosa (Couchbase) - Saga Pattern | Application Transactions Using Microservices
- 📖 Eric Evans - DDD Reference
- 📝 Eric Evans - DDD and Microservices: At Last, Some Boundaries!
- 📖 Domain-Driven Design: The First 15 Years
- 🎞 Jimmy Bogard - Domain-Driven Design: The Good Parts
- 💻 Jakub Pilimon - DDD by Examples
- 📖 DDD Quickly
- 📝 Vaughn Vernon - Reactive DDD: Modeling Uncertainty
- 📖 Pat Helland - Immutability Changes Everything
- 📖 S. Copei, A. Zündorf - Commutative Event Sourcing vs. Triple Graph Grammars
- 📖 C. Mohan, D. Haderle, B. Lindsay, H. Pirahesh and P. Schwarz - ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging
- 📖 P. O'Neil, E. Cheng, D. Gawlick, E. O'Neil - The Log-Structured Merge-Tree (LSM-Tree)
- 📝 Kacper Gunia - EventStoreDB vs Kafka
- 📝 Anton Stöckl - Event Sourcing: Why Kafka is not suitable as an Event Store
- 📝 Domenic Cassini - Why is Kafka not Ideal for Event Sourcing?
- 📝 Vijay Nair - Axon and Kafka - How does Axon compare to Apache Kafka?
- 📝 Jesper Hammarbäck - Apache Kafka is not for Event Sourcing
- 🎞 Udi Dahan - Event Sourcing @ DDDEU 2020 Keynote
- 🎞 Andrzej Ludwikowski - Event Sourcing - what could possibly go wrong?
- 📝 Vikas Hazrati - Event Sourcing – Does it make sense for your business?
- 📝 Mikhail Shilkov - Event Sourcing and IO Complexity
- 📝 Dennis Doomen - The Ugly of Event Sourcing - Real-world Production Issues
- 📝 Hugo Rocha - What they don’t tell you about event sourcing
- 📝 Oskar uit de Bos - Stop overselling Event Sourcing as the silver bullet to microservice architectures
- 📝 Confluent - Event sourcing, CQRS, stream processing and Apache Kafka: What's the connection?
- 🎞 InfoQ - Building Microservices with Event Sourcing and CQRS
- 📝 Chris Kiehl - Don't Let the Internet Dupe You, Event Sourcing is Hard
- 📝 AWS - Event sourcing pattern
- 📝 Event sourcing with Kafka Streams
- 📝 Event Sourcing with Kafka and ksqlDB
- 📝 Hands On: Trying Out Event Sourcing with Confluent Cloud
- 📝 Andela - Building Scalable Applications Using Event Sourcing and CQRS
- 📝 WiX Engineering - The Reactive Monolith - How to Move from CRUD to Event Sourcing
- 📝 Nexocode - CQRS and Event Sourcing as an antidote for problems with retrieving application states
- 📝 coMakeIT - Event sourcing and CQRS in Action
- 📝 Debezium - Distributed Data for Microservices — Event Sourcing vs. Change Data Capture
- 📝 Codurance - CQRS and Event Sourcing for dummies
- 📝 Slalom Build - Event Sourcing with AWS Lambda
- 📝 AWS Prescriptive Guidance - Decompose monoliths into microservices by using CQRS and event sourcing
- 📝 Zartis - Event Sourcing with CQRS
- 📝 Nordstrom - Event-sourcing at Nordstrom: Part 1
- 📝 Nordstrom - Event-sourcing at Nordstrom: Part 2
- 📝 What is Event Sourcing Design Pattern in Microservice Architecture? How does it work?
- 🎞 Techtter - CQRS - Event Sourcing || Deep Dive on Building Event Driven Systems
- 🎞 Tech Mind Factory - Event Sourcing with Azure SQL and Entity Framework Core
- 🎞 Tech Primers - Event Sourcing & CQRS | Stock Exchange Microservices Architecture | System Design Primer
- 🎞 International JavaScript Conference - DDD, event sourcing and CQRS – theory and practice
- 🎞 Event Sourcing in NodeJS / Typescript - ESaucy
- 🎞 Kansas City Spring User Group - Event Sourcing from Scratch with Apache Kafka and Spring
- 🎞 jeeconf - Building event sourced systems with Kafka Streams
- 🎞 Jfokus - Event sourcing in practise - lessons learned
- 🎞 MecaHumArduino - Event Sourcing on AWS - Serverless Patterns YOU HAVE To Know About
- 🎞 Oracle Developers - Event Sourcing, Distributed Systems, and CQRS with Java EE
- 🎞 Creating a Blueprint for Microservices and Event Sourcing on AWS
- 🎞 Azure Cosmos DB Conf - Implementing an Event Sourcing strategy on Azure
- 📝 CosmosDB DevBlog - Create a Java Azure Cosmos DB Function Trigger using Visual Studio Code in 2 minutes!
- 📝 Towards Data Science - The Design of an Event Store
- 📝 Aspnetrun - CQRS and Event Sourcing in Event Driven Architecture of Ordering Microservices
- 📝 Why Microservices Should use Event Sourcing
- 📝 Event-driven architecture with microservices using event sourcing and CQRS
- 📝 Datomic: Event Sourcing without the hassle
If you're interested in Architecture resources, check my other repository: https://github.com/oskardudycz/ArchitectureWeekly/.
It contains a weekly updated list of materials I found valuable and educational.
This blog is licensed under License Creative Commons BY-SA 4.0.
EventSourcing.NetCore is Copyright © 2017-2022 Oskar Dudycz and other contributors under the MIT license.