实验地址:http://nil.csail.mit.edu/6.824/2021/labs/lab-raft.html
目录:
本实验将实现 Raft 共识协议,实验内容主要分为了以下四个模块:
- Part 2A: leader election
- Leader 选举,实现 Raft Leader 选举和心跳检测功能。
- Part 2B: log
- 日志复制,实现 Leader 与 Follower 的日志复制功能。
- Part 2C: persistence
- 持久化,实现 Raft 关键状态的持久化保存与读取。
- Part 2D: log compaction
- 日志压缩,实现日志的快照压缩与安装快照等功能。
Raft 应用层通过 Make() 接口新建 Raft server,其接口定义如下:
func Make(peers []*labrpc.ClientEnd, me int,
persister *Persister, applyCh chan ApplyMsg) *Raft {...}peers []*labrpc.ClientEnd: 包含 Raft 集群的全部端口号me int: 该节点端口号persister *Persister: 用于数据持久化applyCh chan ApplyMsg: 用于 Raft server 通知应用层进行 apply
整个节点启动流程如下:
- 初始化 Raft Node 结构体;
- 通过 persister 读取已持久化的数据;
- 随机化选举超时时间,并启动选举超时计时器;
- 启动 apply 监听协程,用于监听 Raft server commit 状态,并通知上层应用 apply。
Raft Node 结构体定义:
type Raft struct {
mu sync.Mutex // 互斥锁
peers []*labrpc.ClientEnd // 保存所有 peers 的 RPC end points
persister *Persister // 用于保存非易失数据
me int // 记录当前节点索引
dead int32 // 标记节点存活状态
// Non-Volatile 非易失参数 - 需写入磁盘持久化保存 (all servers)
currentTerm int // 当前任期(初始为 0 且单调递增)
votedFor int // 当前任期投票选择的候选者 ID(初值为 null)
logs []LogEntry // 日志记录,每条日志保存了该日志的任期与其包含的状态机的命令
commitIndex int // 最大已提交索引(初始为 0 且单调递增)
lastIncludeIndex int // 快照中最后一个日志的索引
lastIncludeTerm int // 快照中最后一个日志对应的任期
// Volatile 易失参数 - 仅保存于内存 (all servers)
lastApplied int // 当前应用到状态机的最大索引(初始为 0 且单调递增)
nextIndex []int // 将要发送给 follower 下一个 entry 的索引
matchIndex []int // follower 已完成同步的最高日志项的索引
// 自定义的必需变量
voteCounts int // 统计当前获得票数
currentState State // 记录节点当前状态
// 选举超时计时器
electionTimer *time.Timer
timerLock sync.Mutex
// 心跳计时器
heartbeatTimer *time.Timer
heartbeatTimerLock sync.Mutex
// 应用层的提交队列
applyCh chan ApplyMsg
applyCond *sync.Cond // 用于在 commit 新条目后,唤醒 apply goroutine
}Raft 节点状态定义:
type State int
const (
StateLeader State = 1
StateCandidate State = 2
StateFollower State = 3
StateError State = 4
StateShutdown State = 5
StateEnd State = 6
)Leader 选举流程 - 函数调用图:
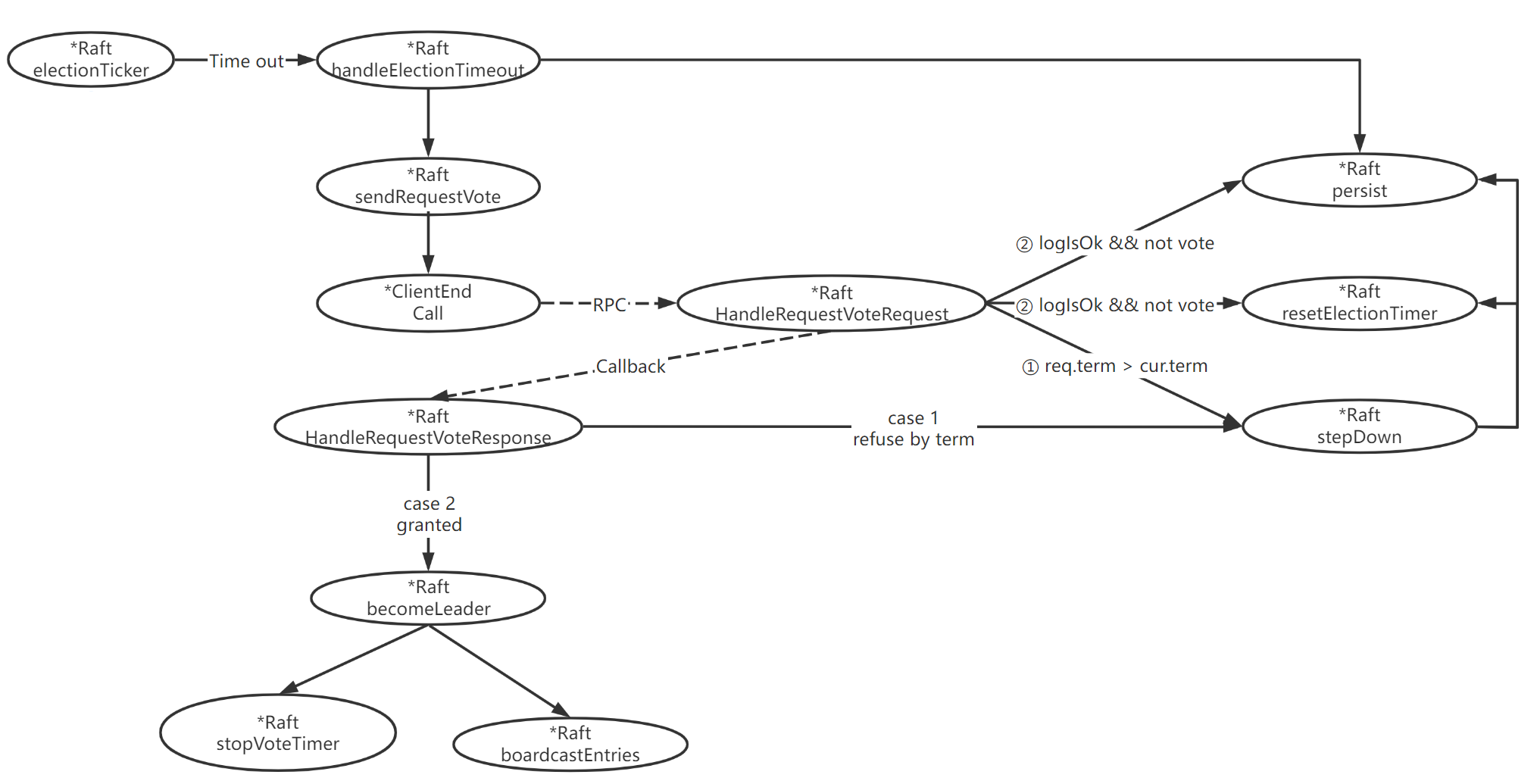
electionTicker:选举定时器,超时将触发选举流程。electionTicker会在 Raft server 初始化时作为后台协程启动,并运行在整个 Raft server 生命周期内。electionTicker通过electionTimer选举超时计时器实现计时,而每次重置electionTimer计时器时均会随机选举超时时间,以降低多个节点同时发起选举,导致选票被瓜分的概率。- 定时器判断超时后,将会调用
handleElectionTimeout方法,发起选举。
handleElectionTimeout:处理 election timeout 选举超时,发起选举。- 在发起投票之前,首先需要判断自己状态非 leader,如果当前状态已经是 leader 则直接返回。
- 在确保状态非 leader 后,执行以下步骤:
- 变为 candidate 状态;
- 自身 term + 1;
- 投票给自己,并统计自己的选票;
- 持久化状态;
- 遍历整个集群,发起拉票请求。
HandleRequestVoteRequest:处理来自 candidate 的拉票请求。- 首先判断 request 中的 term 是否小于自身 term,若小于,则直接忽略;
- 判断节点在该 term 是否已经投过票了,若已投则直接忽略;
- 判断 request 中的 term 是否大于自身 term,若是则执行
stepDown更新状态; - 最终如果收到 request 中的日志不落后于自身的日志,且自身还未投票,投票给这个节点,并更新自己的选举计时器,同时持久化状态。
stepDown:将节点状态回退为 follower,并更新相关状态。- 通常发生于节点收到一个 term 比自身大的消息时,此时可能代表集群选出了一个新的 leader 或是某节点发起了选举。
- 首先将自身状态变为 follower;
- 修改自身 term 为收到的最新的 term;
- 更改为未投票状态;
- 重置选举超时计时器;
- 持久化状态。
HandleRequestVoteResponse:candidate 处理拉票响应。- 首先判断确保当前节点状态仍然是 candidate,若不是,则直接返回;
- 判断自身任期与响应中的任期是否匹配,如果不匹配则直接返回;
- 判断 response 中的 term 是否大于自身 term,若是则执行
stepDown更新状态; - 统计选票,若统计获得超过半数选票则调用
becomeLeader当选 leader。
becomeLeader:candidate 赢得选举后当选 leader。- 首先更改自身状态为 Leader;
- 停止选举超时计时器;
- 立刻并行向集群中的所有节点发起心跳广播,通知自身 Leader 身份。
1. RequestVote RPC 结构定义
type RequestVoteRequest struct {
Term int // candidate 任期
CandidateId int // candidate id
LastLogIndex int // candidate 最后一条日志的索引
LastLogTerm int // candidate 最后一条日志的任期
}
type RequestVoteResponse struct {
Term int // 选民当前任期,用于 candidate 更新自身信息
VoteGranted bool // 选民是否投票给 candidate,true 表示同意
}2. handleElectionTimeout 处理 election timeout 选举超时 - 发起选举
func (rf *Raft) handleElectionTimeout() {
rf.mu.Lock()
defer rf.mu.Unlock()
if rf.currentState != StateLeader {
rf.currentState = StateCandidate // 变为 candidate 状态
rf.currentTerm++ // 自身 term + 1
rf.votedFor = rf.me // 投票给自己
rf.voteCounts = 1 // 计票
rf.persist() // 持久化状态
request := RequestVoteRequest{
Term: rf.currentTerm,
CandidateId: rf.me,
LastLogIndex: rf.lastLogIndex(),
LastLogTerm: rf.lastLogTerm(),
}
// 遍历整个集群,请求投票
for server := range rf.peers {
if server == rf.me {
continue
}
go func(server int, currentTerm int, request RequestVoteRequest) {
var response RequestVoteResponse
ok := rf.sendRequestVote(server, &request, &response) // 发起 RPC
if ok {
rf.HandleRequestVoteResponse(currentTerm, response) // Callback
}
}(server, rf.currentTerm, request)
}
}
}3. HandleRequestVoteRequest 处理来自 candidate 的拉票请求
func (rf *Raft) HandleRequestVoteRequest(request *RequestVoteRequest, response *RequestVoteResponse) {
rf.mu.Lock()
defer rf.mu.Unlock()
// case 1. 收到 request 中的 term < 自身 term
if request.Term < rf.currentTerm {
return
}
// case 2. 收到 request 中的 term == 自身 term,但该 term 已经投过票了(一个 term 只能投一次票)
if request.Term == rf.currentTerm && rf.votedFor != -1 && rf.votedFor != request.CandidateId {
return
}
// case 3.1 收到 request 中的 term > 自身 term
if request.Term > rf.currentTerm {
rf.stepDown(request.Term)
}
// case 3.2 收到 request 中的日志 >= (不落后)于自身的日志,且自身还未投票
logIsOk := request.LastLogTerm > rf.lastLogTerm() || (request.LastLogTerm == rf.lastLogTerm() && request.LastLogIndex >= rf.lastLogIndex())
if logIsOk && rf.votedFor == -1 {
rf.votedFor = request.CandidateId
rf.persist()
rf.resetElectionTimer()
}
response.Term = rf.currentTerm
response.VoteGranted = rf.currentTerm == request.Term && rf.votedFor == request.CandidateId
}4. candidate 处理拉票响应
func (rf *Raft) HandleRequestVoteResponse(term int, response RequestVoteResponse) {
rf.mu.Lock()
defer rf.mu.Unlock()
// 确保当前节点状态为 candidate
// 可能情况:当前节点已经当选成功,节点成为了 leader 或 回退为 follower
if rf.currentState != StateCandidate {
return
}
// 确保 RequestVoteResponse 未过期
// 可能情况:网络拥塞,收到了旧任期时的 Response
if term != rf.currentTerm {
return
}
// 收到 response 中的 term > 自身 term - 进行状态回退
if response.Term > rf.currentTerm {
rf.stepDown(response.Term)
return
}
// 统计选票
if response.VoteGranted {
rf.voteCounts++
if rf.voteCounts >= len(rf.peers)/2+1 {
rf.becomeLeader()
}
}
}日志复制流程 - 函数调用图:
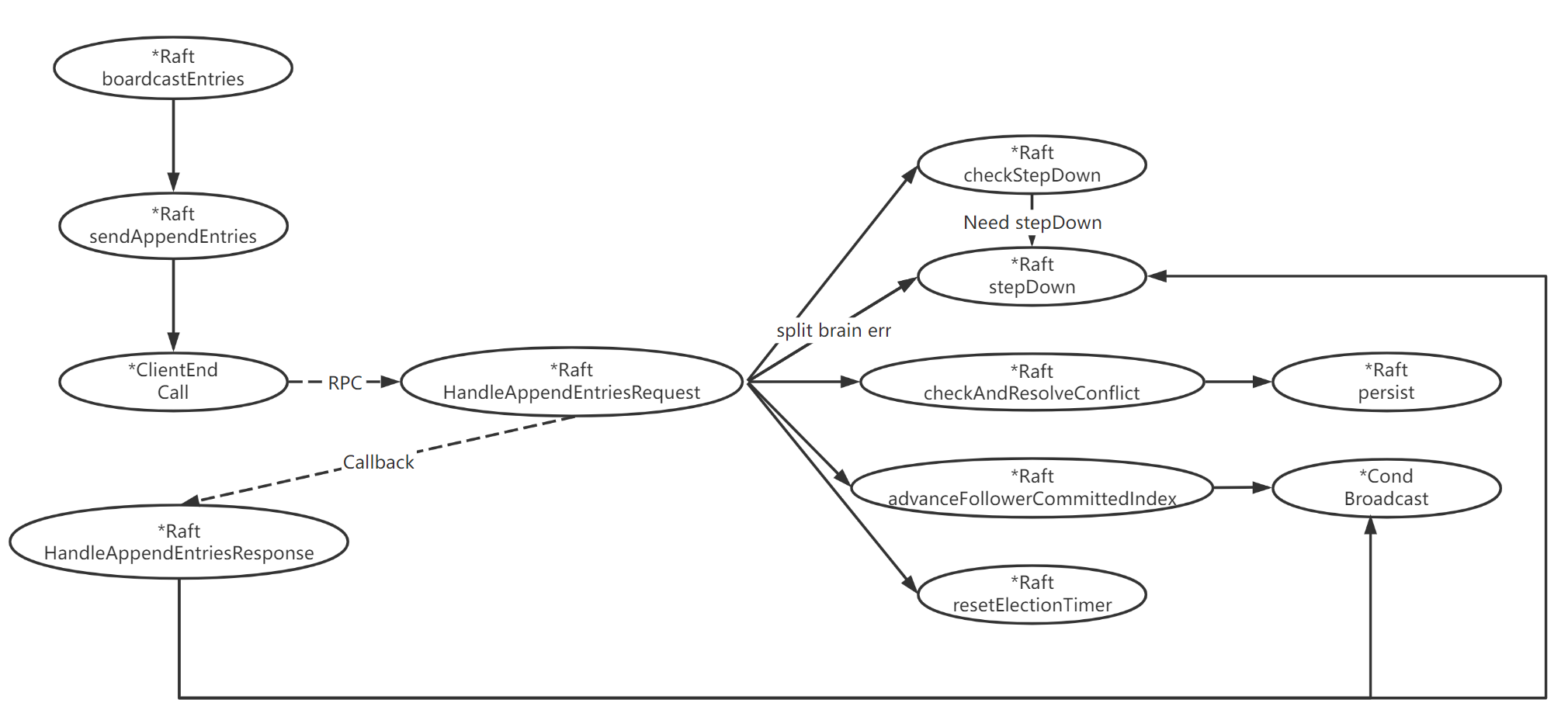
boardCastEntries:心跳广播 & 追加日志。- Raft 心跳与追加日志共用该函数,当 append entries 为空时,表示心跳,非空时,表示追加日志。
boardCastEntries会遍历整个 Raft 集群,检查为每个节点所维护的nextIndex与当前快照检查点的大小,判断是发送日志,还是安装快照,如果当前nextIndex比快照检查点更新,则选择发送日志。
HandleAppendEntriesRequest:follower 处理 append entries RPC 请求。- 首先判断 request 中的 term 是否小于自身 term,若小于,则直接忽略;
- 调用
checkStepDown判断是否需要状态回退; - 判断是否出现脑裂错误,若是则提升自身 term,让发生脑裂的节点,状态回退;
- 判断日志是否匹配;
- 判断是否为心跳;
- 检查日志冲突并解决;
- 最后尝试推进 committed Index。
checkStepDown:检查 term 与 state 以判断是否需要状态回退。- 如果出现以下三种情况之一,均需要调用
stepDown进行状态回退:- Raft node 接收到来自拥有更高 term 的新 leader 的信息;
- candidate 收到来自同一 term 的新 leader 的信息;
- follower 收到来自同一 term 的新 leader 的信息;
- 保存当前 Leader id。
- 如果出现以下三种情况之一,均需要调用
checkAndResolveConflict:检查日志冲突并解决。- 判断收到的 entries 是否已经 apply,如果是,则直接忽略。
- 判断收到的 entries 是否跟自身
lastLogIndex冲突,如果没有冲突,则直接追加,否则删掉自身冲突的 entries 然后追加收到的全部 entries。
advanceFollowerCommittedIndex:尝试推进 committed Index。- 判断 commit index 是否增大,如果是,则更新自身
lastCommitIndex并唤醒 apply 协程进行 apply。
- 判断 commit index 是否增大,如果是,则更新自身
handleAppendEntriesResponse:Leader 处理 append entry RPC 响应。- 判断 response 中的 term 是否大于自身 term,若是则执行
stepDown更新状态; - 判断自身任期与响应中的任期是否匹配,如果不匹配则直接返回;
- 如果 response 返回为 false 则更新
nextIndex,并等待重发; - 如果 response 返回为 true 则更新
nextIndex并判断是否收到了过半数选票,若是则推进commit index。
- 判断 response 中的 term 是否大于自身 term,若是则执行
1. AppendEntries RPC 结构定义
type AppendEntriesRequest struct {
Term int // Leader 当前任期
LeaderId int // Leader id,用于 follower 重定向到 leader
PrevLogIndex int // 前继日志的索引
PrevLogTerm int // 前继日志的任期
Entries []LogEntry // 待追加 log Entries,为空时代表心跳
LeaderCommit int // Leader commit index
}
type AppendEntriesResponse struct {
Term int // follower 当前任期,用于 leader 更新自身信息
Success bool // 返回 true,当 follower 包含的 entry 信息与 PrevLogIndex 和 PrevLogTerm 相匹配
FollowerCommittedIndex int // follower committed Index
}2. HandleAppendEntriesRequest follower 处理 append entries RPC 请求
func (rf *Raft) HandleAppendEntriesRequest(request *AppendEntriesRequest, response *AppendEntriesResponse) {
rf.mu.Lock()
defer rf.mu.Unlock()
// request.Term < 自身 term - 直接忽略
if request.Term < rf.currentTerm {
response.Term = rf.currentTerm
response.Success = false
return
}
// 判断是否需要 step down
rf.checkStepDown(request.Term, request.LeaderId)
// 出现脑裂错误
if rf.votedFor != request.LeaderId {
// 通过使自身 term + 1 让发生脑裂的 leader step down,以最小化脑裂损失
rf.stepDown(request.Term + 1)
response.Success = false
response.Term = request.Term + 1
return
}
// 日志不匹配
if request.PrevLogIndex > rf.lastLogIndex() || // follower 日志落后于 leader 且存在 gap
request.PrevLogIndex < rf.lastIncludeIndex || // 当前 index 涉及已执行快照部分
(request.PrevLogTerm != 0 && request.PrevLogTerm != rf.getLogTermWithIndex(request.PrevLogIndex)) {
// 告知 leader 自身 commit index,请求 leader 以该 index 为起点发送
response.FollowerCommitedIndex = rf.commitIndex
response.Term = rf.currentTerm
response.Success = false
rf.resetElectionTimer()
return
}
// 判断是否为心跳
if len(request.Entries) == 0 {
rf.advanceFollowerCommittedIndex(request.LeaderCommit)
response.FollowerCommitedIndex = rf.commitIndex
response.Term = rf.currentTerm
response.Success = true
rf.resetElectionTimer()
return
}
// 检查日志冲突并解决
if !rf.checkAndResolveConflict(request) {
response.Success = false
response.Term = rf.currentTerm
response.FollowerCommitedIndex = rf.commitIndex
return
}
// 尝试推进 committed Index
rf.advanceFollowerCommittedIndex(request.LeaderCommit)
response.FollowerCommitedIndex = rf.commitIndex
response.Term = rf.currentTerm
response.Success = true
rf.resetElectionTimer()
}3. checkStepDown 检查的 term 与 state 以判断是否需要状态回退
func (rf *Raft) checkStepDown(requestTerm int, leaderId int) {
if requestTerm > rf.currentTerm {
// Raft node 接收到来自拥有更高 term 的新 leader 的信息
rf.stepDown(requestTerm)
} else if rf.currentState != StateFollower {
// candidate 收到来自同一 term 的新 leader 的信息
rf.stepDown(requestTerm)
} else if rf.votedFor == -1 {
// follower 收到来自同一 term 的新 leader 的信息
rf.stepDown(requestTerm)
}
// 保存当前 leader
if rf.votedFor == -1 {
rf.votedFor = leaderId
}
}4. handleAppendEntriesResponse Leader 处理 append entry RPC 响应
func (rf *Raft) handleAppendEntriesResponse(server int, request *AppendEntriesRequest, response *AppendEntriesResponse) {
rf.mu.Lock()
defer rf.mu.Unlock()
// response 中的 term 大于自身 term,执行状态回退
if response.Term > rf.currentTerm {
rf.stepDown(response.Term)
return
}
// 收到了过期的 RPC 回复
if request.Term != rf.currentTerm || response.Term != rf.currentTerm {
return
}
if !response.Success {
// 收到 false,根据响应回复,更新 nextIndex
rf.nextIndex[server] = response.FollowerCommitedIndex + 1
} else {
// 收到了正确的回答,修改对应 matchIndex 和 nextIndex
prev := rf.matchIndex[server]
rf.matchIndex[server] = Max(rf.matchIndex[server], request.PrevLogIndex+len(request.Entries))
now := rf.matchIndex[server]
rf.nextIndex[server] = Max(request.PrevLogIndex+len(request.Entries)+1, rf.matchIndex[server])
// 尝试推进 commit index
if prev != now {
sortMatchIndex := make([]int, 0)
sortMatchIndex = append(sortMatchIndex, rf.lastLogIndex())
for i, value := range rf.matchIndex {
if i == rf.me {
continue
}
sortMatchIndex = append(sortMatchIndex, value)
}
sort.Ints(sortMatchIndex)
midIndex := len(rf.peers) / 2
if len(rf.peers)%2 == 0 {
midIndex--
}
newCommitIndex := sortMatchIndex[midIndex]
// 确保不能提交上一任期的日志
if newCommitIndex > rf.commitIndex && rf.getLogTermWithIndex(newCommitIndex) == rf.currentTerm {
rf.commitIndex = newCommitIndex
rf.applyCond.Broadcast()
}
}
}
}实验数据的持久化需要使用 Persister 对象封装好的 persist 接口,该接口出于实验测试的目的,实际上并没有真正的落盘,而是将其保存到了其他内存中。
Raft 持久化设计,首先要明确需要持久化的参数,然后在每次修改后,调用 persist 持久化即可。
func (rf *Raft) persist() {
w := new(bytes.Buffer)
e := labgob.NewEncoder(w)
e.Encode(rf.currentTerm) // 节点当前任期
e.Encode(rf.votedFor) // 当前任期投票选择的候选者 ID
e.Encode(rf.commitIndex) // 最大已提交索引
e.Encode(rf.lastIncludeIndex) // 快照中最后一个日志的索引
e.Encode(rf.lastIncludeTerm) // 快照中最后一个日志对应的任期
e.Encode(rf.logs) // 日志记录
data := w.Bytes()
rf.persister.SaveRaftState(data)
}日志压缩流程 - 函数调用图:
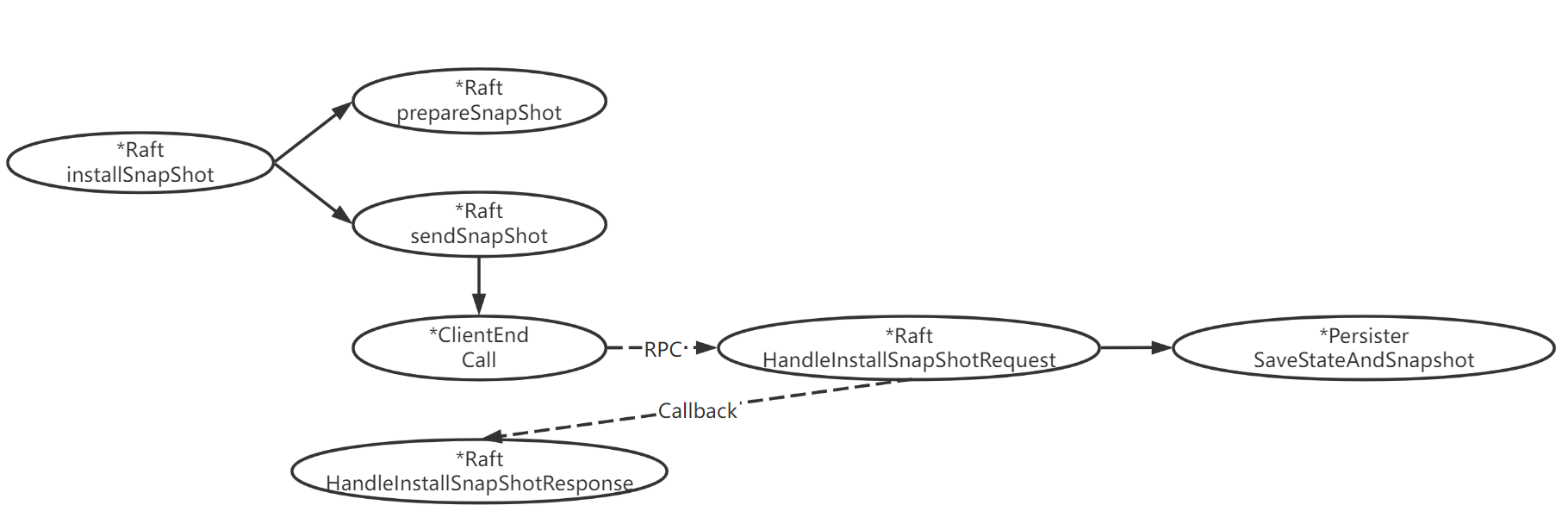
Snapshot:用于应用层调用,创建一个快照。- 首先确保创建快照的 index 索引大于当前最新快照中的最后一个日志对应的索引,若否,则直接返回;
- 保存快照 index 之后的所有日志;
- 保存快照状态、快照中最后一个日志的索引与对应的任期;
- 删除快照之前的日志。
InstallSnapShot:Leader 为较为落后的 follower 安装快照。- Leader 将首先调用
prepareSnapShot读取自身最新的快照,构造InstallSnapShotRequest然后调用sendSnapShot发起 RPC。
- Leader 将首先调用
HandleInstallSnapShotRequest:Follower 处理来自 leader 的安装快照请求。- 首先判断 request 中的 term 是否大于自身 term,如果是则直接忽略并返回;
- 判断自身状态是否是 follower,如果不是则执行
stepDown; - 判断自身快照状态是否大于最新的快照状态,如果是则直接返回;
- 如果自身日志比快照更新,则首先保存在这之后的日志,然后再保存快照,最后删掉更旧的日志。
- 调用持久化方法
SaveStateAndSnapshot保存。
HandleInstallSnapShotResponse:Leader 处理安装快照响应。- 判断自身状态是否仍是 leader,如果不是则直接返回;
- 判断 term 是否匹配,如果 term 更大,则执行
stepDown; - 更新 follower 的
matchIndex和nextIndex。
InstallSnapshot RPC 结构定义
type InstallSnapshotArgs struct {
Term int // Leader 当前任期
LeaderId int // Leader id,用于 follower 重定向到 leader
LastIncludedIndex int // 快照所包含的最后一条日志的 index
LastIncludedTerm int // 快照所包含的最后一条日志的 term
Data []byte // 快照数据
}
type InstallSnapshotReply struct {
Term int // follower 当前任期,用于 leader 更新自身信息
}完成所有实验后,可通过 go test -race 命令,同时测试全部 Lab 2A - 2D,测试结果如下: