
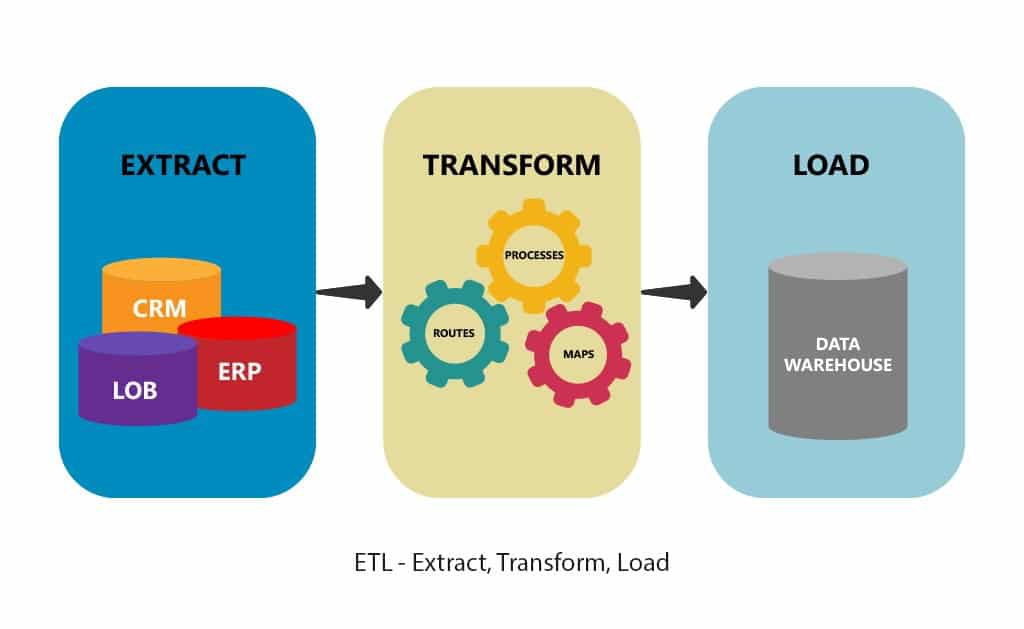
ETL Pipeline (Source: Google Images)
{kind=link}
The link to medium article can be found here
In this example, we'll write a full ETL pipeline for the GDP data. That means we'll extract the World Bank data (taken from https://data.worldbank.org), transform the data, and load the data all in one go. In other words, we'll want one Python script that can do the entire process.
Why would we want to do this? Imagine working for a company that creates new data every day. As new data comes in, we'll want to write software that periodically and automatically extracts, transforms, and loads the data.
We'll extract the GDP data one line at a time. We'll then transform that line of data and load the results into a SQLite database.
Here is an explanation of how this Jupyter notebook is organized:
- The first cell connects to a SQLite database called worldbank.db and creates a table to hold the gdp data.
- The second cell has a function called extract_line(). This function is a Python generator. A generator is like a regular function except instead of a return statement, a generator has a yield statement. Generators allow us to use functions in a for loop. In essence, this function will allow us to read in a data file one line at a time, run a transformation on that row of data, and then move on to the next row in the file.
- The third cell contains a function called transform_indicator_data(). This function receives a line from the csv file and transforms the data in preparation for a load step.
- The fourth cell contains a function called load_indicator_data(), which loads the trasnformed data into the gdp table in the worldbank.db database.
- The fifth cell runs the ETL pipeilne
- The sixth cell runs a query against the database to make sure everything worked correctly.
Note: This example is taken from Udacity's Data Scientist Nano degree program