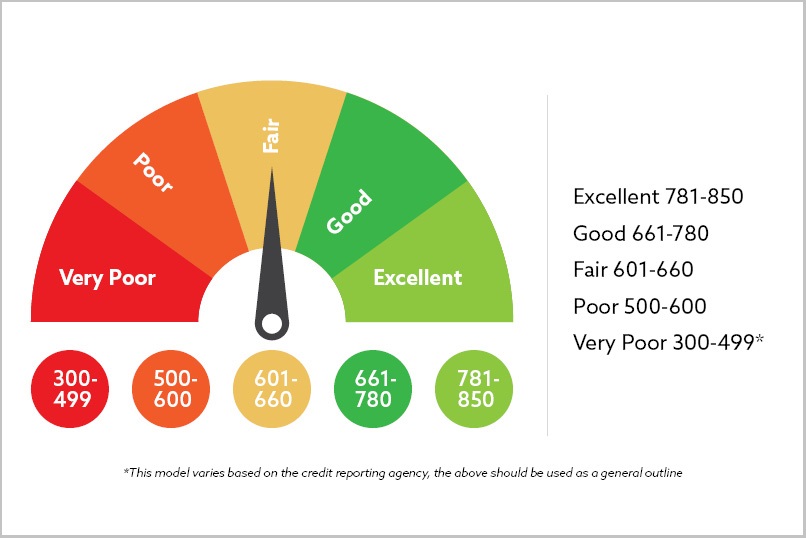
Figure 1: Credit Score Illustration (Source).
In this project, we developed and deployed a credit score model using Logistic Regression and Weight of Evidence techniques. The scoring is based on the "point to double the odds" method, which uses Logistic Regression parameters, Weight of Evidence, and some user-defined rules to assign credit points for each predictor variable. Unlike our previous projects, this credit score model was built manually without the help of optbinning. We’ve deployed the model as an API endpoint, using FastAPI for the API, Azure Container Services for hosting, and a Streamlit app for the user interface.
The goal of this project isn’t just to build a reliable credit score model and create a detailed credit scorecard, but also to focus on deploying the model through a web application. This includes concepts like Python package development, continuous integration, and continuous deployment.
The project is built using Python 3.10, with the following libraries and tools:
PandasandNumpyfor data manipulation.MatplotlibandSeabornfor data visualization.Scikit-learnfor training and evaluation credit score model.FastAPIfor API development.Streamlitfor the development of the web application.Azure Container Servicesfor hosting API services.
To run this project locally, you can use Anaconda. Ensure your Python version is 3.10. Recommended using linux environment for setting up environment. Then, install the required libraries from the requirements.txt file:
make create_environment # create conda environment
conda activate credit-score-mlops # access the environment
make requirements # install all libraries from the requirements.txt file
make create_ipykernel # create ipykernelWith this you can use run the Python notebook using the exact same dependencies that I used for this project. For the web application you can access through this link: https://huggingface.co/spaces/marcellinus-witarsah/credit-score-app-v2.